딥러닝 기술 활용을 위한 데이터셋 구축방법 연구 : CNN을 활용한 데이터셋과 하이퍼파라미터 조정을 통한 정확도 개선
Copyright ⓒ 2023 The Digital Contents Society
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-CommercialLicense(http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.

초록
본 연구의 목표는 통상적으로 AI학습 데이터셋을 구축하기 위해 활용하는 프로세스의 요구조건과 동적주제도 구축분야에 적합한 형식의 프로세스를 설계하기 위한 요구조건을 정의하는 것이다. 동적정보는 시시각각 변화하는 정보를 의미하며 데이터의 수가 많지 않고 데이터셋 구축의 과정에 많은 시간이 소요된다. 이에 따라 동적정보 기반의 AI 기술개발은 데이터기반의 학습이 요구되며 시행착오를 통해 문제를 신속하게 해결해가는 과정을 필요로 한다. 본 논문에서는 딥러닝 기술의 인식 정확도를 높이기 위해, 작업한 이미지와 모델 및 학습과정을 보완하는 절차를 정의하고자 한다. 본 논문의 절차를 통해 사용자가 다양한 유형의 클래스를 포함하는 데이터셋을 토대로 AI 학습 모델의 정확도를 확보할 수 있게 한다. 또한 사용자가 균열이 비균열로 인식되는 경우의 비율을 최소화하기 위해 딥러닝 변수들을 조율함으로써 정확도와 검증 정확도를 유사하게 조정할 수 있게 한다.
Abstract
The goal of this study is to define the requirements for the process used to build AI learning datasets and the requirements for designing a process suitable for the field of dynamic subject map construction. Dynamic information refers to information that changes every moment, and the number of data is not large, and the process of constructing a dataset takes a lot of time. To introduce AI in dynamic information fields, data-based learning and processes based on ‘prototyping’ are required. In this paper, in order to increase the recognition accuracy of deep learning technology, the process of supplementing the working image, model, and learning process need to be defined. The process in this paper enables users to secure the accuracy of AI learning models based on datasets containing various types of classes. Also, it also allows users to similarly adjust accuracy and verification accuracy by tuning deep learning parameters to minimize the percentage of cases where cracks are recognized as non-cracks.
Keywords:
Convolutional Neural Network, Deep learning, Dataset, Hyperparameter, Accuracy키워드:
합성곱신경망, 딥러닝, 데이터셋, 학습매개변수, 정확도Ⅰ. 서 론
1-1 연구의 배경 및 목적
현재까지 인공지능의 기술은 다양한 연구를 통해 모델의 정확도를 개선하는 측면에서 발전을 해왔다. 건설분야에서 인공지능 기술은 노동력 부족에 대응하거나 생산성을 향상시키기 위한 수단으로 도입되고 있다[1]. 현대건설의 경우 기계분야에서 활발히 연구되고 있는 로봇기술에 인공지능 모듈을 탑재하고 시공현장의 천장 타공작업에 적용하고 있다.
현 단계에서 인공지능 기술이 도약하기 위해서 데이터셋을 활용해서 정확도를 개선할 수 있는 방법을 찾는 것이 관건이다. 건설분야에서 데이터 구축사업의 성장 가능성이 높게 평가되고 있을 뿐 아니라 신규 투자액은 약 10조원에 달할 것으로 예상된다[2]. 이는 대량의 데이터 학습은 모델 성능의 향상과 직결되며 정확도 향상에도 매우 중요한 요소이기 때문이다.
그러나 건설분야의 데이터구축은 특이점을 갖고 있다. 복잡한 산업구조로 인해 절차의 표준화가 어렵고 데이터 획득을 위한 통제요인(예: 건설현장에 존재하는 장비와 근로자, 실시간 촬영요건 등)이 다양하기 때문이다. 따라서 건설분야에서 인공지능 학습을 위한 데이터는 대량의 데이터셋보다는 소량의 데이터셋을 기반으로 결과의 정확도를 높이는 방법이 필요하다.
건설절차는 표준화가 어렵기 때문에 ‘프로토타이핑’과 같이 실제로 구현해보고 문제를 신속하게 해결(Fast fail, fast learn)해가는 과정이 필요하다. 현재의 딥러닝 기술은 수많은 레이블을 기반으로 한 연쇄적인 판단력을 향상시키기 위한 “모델 기반의 학습”에 초점을 맞추고 있다. “모델 중심의 개발”은 모델의 구조를 변화시킴으로써 정확도를 향상시키는 것인데, 이에 더하여 일관적인 데이터와 코드 모델을 학습시키는 방법에 대한 “모델 외적인 방법의 개발”도 병행되어야 한다.
건설분야 인공지능의 성공요인은 “데이터셋 구축 방법”과 “하이퍼파라미터 조정 방법”에 있다.
첫째, 학습용 데이터셋은 일관적인 형식으로 제공되어야 한다. 정부는 ‘한국판 디지털 뉴딜사업’, ‘데이터 댐’ 과 같은 사업을 추진하면서 건설분야에서 AI 기술 적용에 요구되는 활용성 높은 데이터셋을 구축하고자 노력하고 있다[3]. 그럼에도 불구하고 데이터셋의 부족문제는 지속적으로 개선이 필요하다. 예를 들어 시설물의 결함이나 안전진단을 위한 데이터는 정보는 수집이 어렵다[4]. 현재 시설물 안전점검은 점검자가 육안으로 수행하며 점검 시 기록된 데이터는 학습에 활용하기 어려운 수준이다. 예를 들어 점검 시 촬영한 이미지의 방향 및 해상도가 다르거나 텍스트로만 기재하여 학습과정에 직접 활용이 어렵다. 또한 시설물의 결함이 있을 경우 즉시 수선에 의해 관련 자료를 취득하기 어렵다. 따라서 적은 양의 데이터셋을 통해 학습 정확도를 달성하는 방법이 필요하다.
둘째, 하이퍼파라미터는 학습의 성능을 결정하는 요소이다. Yu(2020)의 연구는 하이퍼파라미터의 최적화에 관한 내용을 제시한 것이며, 하이퍼파라미터는 크게 두 가지로 구분하였다[5]. 모델의 학습에 관여하는 변수와 모델의 구조와 관련된 변수를 의미한다. 하이퍼파라미터는 개발자의 경험과 지식에 의해 설정되는 것으로서 테스트 결과가 개발자의 목표성능에 부합할 때까지 조정되는 것이다.
본 논문에서 인공지능의 학습결과를 결정하는 데이터셋과 하이퍼파라미터의 조정에 따라 학습결과를 찾아가는 과정을 구현하고자 한다.
1-2 연구의 방법 및 범위
본 논문에서는 딥러닝 정확도에 영향을 미치는 이미지를 분류, 작업한 이미지 현황, 데이터 속성에 따라 인식정확도를 확인 및 보완하는 과정들을 포함한 데이터셋 구축과정을 절차로서 정의하고자 한다.
딥러닝 데이터셋 구축을 위해서 데이터셋의 다양성을 고려하여야 한다. Shim (2020)의 연구는 AI기반 건설기술 사례들을 데이터셋에 직접 적용함으로써 정확도를 비교·검증하였다[6]. 특히 구조물 손상탐지에 관련하여 CNN기반의 학습모델(영상 분류모델, 물체 탐지모델, 물체 세분화모델, instance segmentation 모델, 이하 4가지)에 성능평가 지표를 적용함으로써 학습 정확도를 비교하였다. 이 연구는 콘크리트와 같이 단일 재질을 대상으로 한 것인데, 딥러닝 모델의 설계는 다양한 구조물의 특성이 반영되어야 함을 시사하고 있다. 구조물의 균열 정확도를 향상시키기 위해서 현무암, 벽돌, 목제 등과 같이 균열과 구분되어야할 내장재들의 특성을 반영해야 한다는 것이다.
또한 딥러닝 데이터셋을 구축에 영향을 미치는 하이퍼파라미터를 적정범위로 설정하여야 한다. 학습에 영향을 미치는 요소로서, 하이퍼파라미터의 조절은 필수적이다. CNN은 Convolutional Neural Network (합성곱 연산)의 약자로서 두 함수 f, g 가운데 하나의 함수를 반전(reverse), 전이(shift)시킨 후 다른 하나의 함수와 곱한 결과를 적분하는 것을 뜻한다. 딥러닝에서 가장 많이 활용되는 알고리즘으로서 이미지, 비디오, 텍스트 또는 사운드를 분류하기 위해 활용되며 데이터로부터 직접 학습하고 패턴을 사용하여 이미지를 분류하고 특징을 수동으로 추출할 필요가 없다[7].이미지의 특징 추출단계의 커널의 크기, 채널의 수, Stride 등의 값은 CNN 구조를 결정할 뿐 아니라 특징 추출 및 정확도에 영향을 미친다. Lee (2020)의 연구는 하이퍼파라미터 값을 최적으로 결정할 수 있는 기법을 개발하는 것이었다[8]. CNN의 특징 추출 단계에서의 적절한 커널의 크기와 채널의 수를 구하는 방법을 제안하였다. 이 연구는 상대적으로 정확도가 낮게 분류되는 데이터를 활용했다는 측면에서 차별화된다.
본 논문의 프레임워크는 그림 1과 같다.

Research framework
데이터셋 구성 및 하이퍼파라미터 조정을 통해 정확도 확인하는 과정을 다섯가지 단계로 구성한다.
순서대로 학습용 데이터의 전처리(Data readiness), 이미지 특징 추출(Feature management), 학습 수행(Training management), 모델의 학습결과 도출 및 평가(Model monitoring), 모델의 보완(Model management)의 세 가지 단계로 구성된다. 이 일련의 순서를 세 가지 테스트 셋 변화를 통해 데스트셋과 하이퍼파라미터와 학습 정확도의 연관관계를 파악한다. 첫 번째 테스트셋은 데이터 라벨링을 오픈소스 모델(Sample model)을 통해 학습의 문제를 해결한다. 두 번째 테스트셋은 오픈소스 모델을 기반으로 특징 추출에 관한 모델을 구축함으로써 모델의 구조 및 데이터셋과 정확도 간의 관계를 분석한다. 세 번째 테스트셋은 두 번째 테스트셋의 모델을 기반으로 데이터셋, 모델의 구조, 학습관련 하이퍼파라미터의 조절과 정확도의 관계를 분석한다.
본 논문의 프레임워크의 상세는 그림 2와 같다. 다양한 유형의 클래스를 포함하는 데이터셋을 구축함으로써 AI 학습 모델의 정확도를 확보하고자 한다.

Details of the dataset construction and hyperparameter tuning process
- • 샘플 모델 및 공개 데이터셋 활용을 통한 라벨링 및 문제점 분석 (샘플 모델: CNN 기반의 기초 모델 구축)
- • 샘플 모델 및 구축 데이터셋 활용을 통한 문제점 분석
- • 모델의 변경 및 하이퍼파라미터 변경 및 결과 분석(최적화 포함)
이 절차구축 과정은 이미지를 수집, 레이블링, 훈련 및 최적화하는 일련의 과정을 모델로서 정립하기 위함이다. 이 모델의 정확도를 90% 이상 달성하기 위해 초기에 VGG16을 기반으로 한 CNN 구조를 설계하고 순차적으로 네트워크와 이미지 데이터셋의 변화를 통해 이미지 정확도를 개선한다.
딥러닝 모델의 인풋은 초기에는 공개데이터셋(콘크리트 균열 이미지), 이후에는 직접 촬영한 마감재 이미지 데이터셋으로 구성한다.
데이터셋은 데이터셋의 구축, 데이터셋 증강을 통해 보완한다. 마감재의 특징이 질감을 표현하는 입자에 의해 방해받을 수 있기 때문에 무조건 높은 해상도의 데이터셋을 필요로 하지 않을 것으로 예상한다.
CNN 네트워크는 특징추출과 분류의 두 단계로 나눌 수 있다. 특징 추출은 커널의 크기, 채널의 수와 같은 하이퍼파라미터는 특징을 추출하는 데에 영향을 준다. 이 과정에서 하이퍼파라미터를 최적화하는 과정을 제안한다. 하이퍼파라미터의 변화를 통해 정확도를 비교한다.
II. 딥러닝 환경설정 및 테스트
2-1 데이터 기반 AI 성능 개선 사례
AI기술을 활용하여 이미지를 인식하는 방법이나 절차는 영상처리 분야의 Pascal VOC (Visual Object Classes)의 대회를 기점으로 정형화가 진행되었다. AI기술의 발전은 모델기반의 설계(Model-centric AI)와 데이터기반의 설계(Data-centric AI), 이하 2가지로 나뉜다. 모델 기반의 설계는 AI 모델의 성능을 개선하기 위한 구조와 파라미터(parameter)값을 조정하는 것이다. 데이터 기반의 설계는 데이터셋을 구성하는 방법을 조정하는 것이다.
실제 제조 업계에서 데이터 기반 설계를 통해 운영 및 마케팅, 영업 부문에서 성능개선을 달성하고 있다. 공장 설비에서 주어진 원데이터(Raw Data)로 불량품 분류 모델을 학습했을 때는 53%의 정확도를 보였으나, 데이터 분석을 통하여 잘못된 레이블 4개를 보정 및 제거하여 재학습한 경우 71% 정확도로 크게 성능을 개선할 수 있었다.
또 다른 사례로, 복잡한 웨이퍼 패턴(Wafer Pattern, 미세회로 패턴이 새겨진 기판으로 반도체 집적회로의 핵심 재료)을 군집화(Clustering)하고자 했을 때, 패턴이 고차원으로 매우 복잡하여 전통적인 기법으로는 56% 정확도로 현장에 적용할 수가 없었다. 이 또한 데이터 분석을 통하여 데이터 품질과 모델 정확도에 악영향을 주는 원인이 노이즈성 미세 Pixel들과 카메라 축의 흔들림이라는 것을 파악하였고, 피처 전이 학습(Feature Transfer Learning)을 이용하여 자동으로 노이즈를 보정한 후 군집화한 결과 정확도가 78%로 개선되는 것을 확인한 것이다.
현재 건설분야에서 데이터 기반 설계가 시사하는 바가 크다. AI를 활용하여 건설분야의 이상현상(예: 사고, 파손 등)들을 탐지함으로써 설계, 시공 외 유지관리단계에 이르기까지 생산성을 높이거나 작업의 효율성을 확보하고 있다. 그러나 건설분야에서 데이터셋의 구축에 대해서 여전히 어려움을 호소하고 있다. 건축물의 년수가 30년을 넘어선 “노후 건축물”이 폭발적으로 증가함에 따라 노후 건축물에서 발생할 수 있는 피해를 사전에 미리 대비하는 것이 필요하다[9][10]. 그러나 안전진단의 과정 자체가 모든 유형의 위험사례를 포함하지 않을 뿐 아니라 안전진단을 내리기 위한 인력, 소요시간, 장비 등의 물리적 자원이 소요된다. 딥러닝을 통해 마감재 안전진단을 해결함으로써 마감재 균열 및 탈락으로 발생할 수 있는 안전사고를 사전에 예방할 수 있다. 즉 이상현상을 탐지하는 데에 활용되기 위한 딥러닝 데이터셋 구축방법을 오류와 해결방법을 찾기 위해 데이터셋, 파라미터와 하이퍼파라미터의 연관성을 탐구한다는 측면에서 본 연구의 차별성이 있다.
2-2 모델 구성 및 테스트계획
모델 구성 및 테스트계획은 총 세 가지 단계로 구성하였다.
첫째, 데이터셋을 최소화한다. 데이터를 초기 100장 정도에서 시작하여 1000 ~ 3000장 정도의 학습을 진행한다.
둘째, 데이터셋을 전처리하였다. VGG16를 모방하여 224*224 픽셀의 이미지를 처리하는 모델을 정의한다.
이 모델이 학습-훈련-예측하는 과정에서 이미지 중심을 기준으로 정사각형으로 이미지를 분할하는데, 이 과정에서 균열의 특징을 결정짓는 부분이 학습에 활용되지 못할 수 있다. 또한 균열이 아닌 어두운 음영 부분은 학습 대상의 범위에서 제외하기 위해 삭제하였다.
셋째, 코드를 단순화하였다(그림 3). VGG16의 컨볼루션 레이어의 앞부분을 참조하여 Image Augmentation (이미지 변형 및 증가)과 같이 세부기능을 추가하였다. 적은 양의 데이터를 활용하여 연산을 최소화하여 정확도가 달성되는지 여부를 확인해가며 코드를 변형한다.

A model based on VGG16
넷째, Fully-connected 레이어는 포함하였다. 이 레이어를 사용하지 않고 Convolution layer와 Pooling Layer만 활용하기도 하며, 이미지의 공간정보가 사라진다는 단점은 있으나 입력한 데이터를 분류해준다는 측면에서 활용한다.
테스트과정에서 샘플모델을 기반으로 하는 초기 실험단계를 제외하고 2단계의 모델(그림 1의 Level 2, Level 3)을 다섯가지 유형으로 분류하여 실험을 수행하였다(표 1).구상한 모델들은 아래 그림 4와 같다. Model A와 Model B는 코드구조의 변화에 따라 분류된 유형들이다. AA와 AB는 데이터셋의 변경/보완에 따라 결과가 달라지는지 여부를 확인하기 위한 것이고, AB와 AC는 코드구조의 변화 없이 파라미터 상의 변화로 예측결과에 변화가 있는지 여부를 확인하기 위한 것이다. AB, AC를 통해 구현된 결과가 데이터의 수를 최소화해도 달성가능한지 확인하기 위해 BA를 만들고 BB에서 변수를 변화시킴으로써 정확도를 개선할 수 있는지 여부를 확인한다.

Plan of tests

Detailed model comparison with dataset and hyperparameter tuning
Ⅲ. 테스트 결과
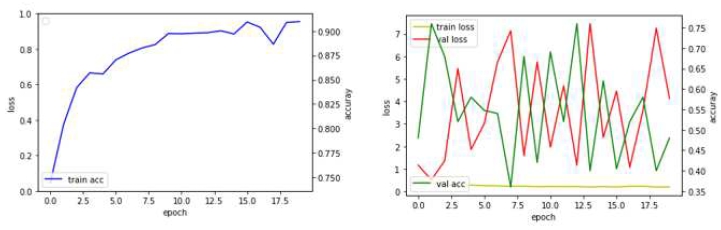
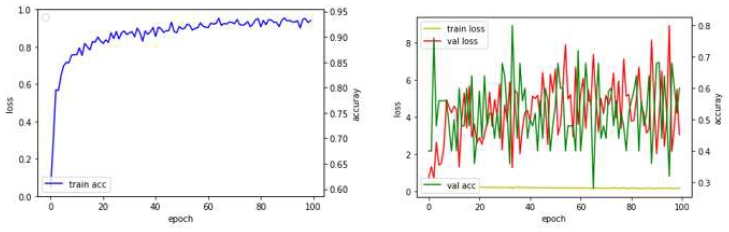
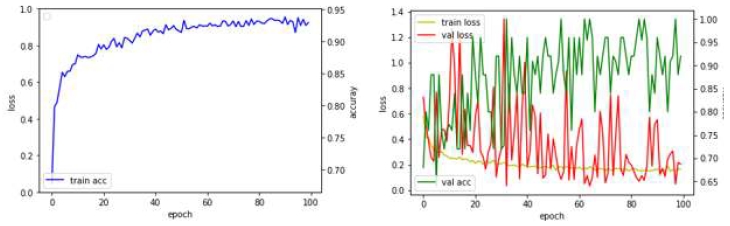
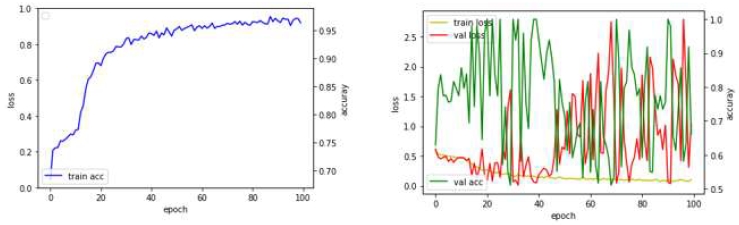
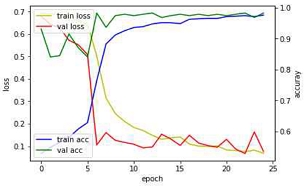
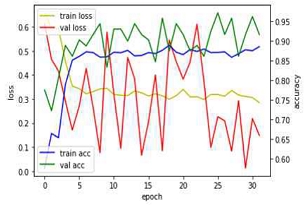
테스트의 과정은 크게 두 가지로 구분하여 설명하고자 한다. 손실 값(Train loss)의 추이는 최적의 값으로 수렴하는 양상을 보여야 한다. 그러나 실험 초기(1차 ~4차, 표 2)에 손실 값이 위 아래로 불규칙하게 진동하는 양상을 보인다. 이후 하이파라미터의 변경(5차 ~ 9차, 표 3)을 통해 진동의 폭을 줄일 수 있었다.
Test results (1st ~ 4th)
Test results (5th ~ 9th)
1차와 2차 실험에 활용된 데이터셋은 도로 교량분야의 균열(Crack)/비균열(non-Crack)에 관한 여러가지 데이터셋을 조합하였고 딥러닝 학습방식은 Model A를 기반으로 하였다. 1차에 정확도는 2차 정확도에 비해 높았다. 1차 정확도가 높았던 이유는 데이터셋의 차이에 있을 것으로 예측된다. 1차의 데이터셋과 2차 데이터셋의 차이는 정면이 아닌 상태에서 촬영되었거나 주변 객체(라바콘, 맨홀, 자동차, 도로 표지판)가 포함된 이미지의 존재여부에 있다.
1, 2차 모델의 문제는 10개의 크랙 이미지(트레이닝, 테스트셋과는 별도의 이미지)를 논-크랙으로 판별하지는 않았다. 반대로 논-크랙의 이미지(노출 콘크리트와 같이 이미지 내 둥근 형태의 홀이 존재하거나 롤러/스페이스 등으로 시공된 다양한 문양의 도장재)를 크랙으로 판별하는 경우가 있었다. 정확도의 변동, 낮은 검증 정확도를 해결하기 위해 데이터셋의 양을 늘리고 이미지 내에 포함되어 있는 주변환경의 이종객체를 제거하였다.
3차 실험 결과에서 학습량의 증가와 여전히 정확도와 검증 정확도에 차이가 있었다. 학습 구조의문제와 사례 이미지의 유형이 다양(도로/교량/벽체의 콘크리트가 모두 포함되어 있음)했기 때문으로 판단된다. 사례 이미지에 포함된 콘크리트가 활용된 위치에 따라 마감방식이 상이하기 때문으로 판단된다. 데이터셋을 동일한 재료로 통일하였다. 그러나 4차 실험 결과에서도 딥러닝 변수의 조정을 거쳤음에도 불구하고 검증 정확도의 차이가 컸다. 이미지 내의 그림자가 드리워진 부분이나 균열의 판단에 영향을 미칠만한 이미지 모서리의 상태를 점검하였다.
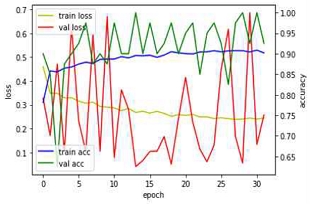
5차부터 9차 실험까지 정확도 및 손실값 측면에서 다른 양상을 보이는 것을 확인할 수 있었다(표 3).
5차 실험 결과에서 데이터셋의 점검과 변수 조정을 통해 검증 정확도가 높아졌다. 딥러닝 변수의 변화를 통해 정확도/검증 정확도의 개선이 됨을 확인할 수 있었다. 단, 데이터셋 외의 이미지를 예측하고자 하였을 때 유사 이미지는 정확하게 판단되나 다른 종류의 콘크리트나 마감재는 예측이 제대로 되지 않았다. 특히 균열인데도 균열이 아닌 것으로 판단하는 심각한 사례들도 있었다. 이에 데이터셋 수, 변수의 설정, 학습과정의 문제 중 어느 것이 요인인지를 알아낼 필요가 있었다.
7, 9차의 경우 초기모델에 비해 학습 데이터량이 적었음에도 불구하고 정확도와 검증정확도가 유사하게 달성되었다. 5, 7차에서는 수치상으로 문제는 없으나 학습데이터와 다른 환경에서 촬영한 이미지와 마감재에 대해서는 예측에 대부분 오류가 있음(16번의 오류/30번 실행)을 확인하였다.
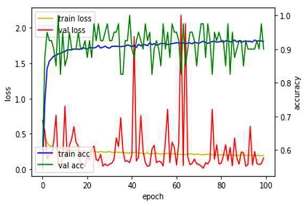
9차의 경우 예측에 대한 오류가 나오지는 않았으나 검증 손실과 학습 손실도가 낮아지기는 하나 다소 높은 상태에서 학습이 종료됨을 볼 수 있었다. 이를 해결하기 위해 데이터셋은 유지하되 코드를 변경하기로 결정(Model B로 적용)하였다. 10차 모델은 (실제, 판단결과) = (크랙, 크랙), (논-크랙, 논-크랙)하였다. 개별 이미지를 업로드해보아도 올바르게 평가. 훈련데이터셋과 전혀 다른 장소에서 촬영된 이미지셋을 업로드해보아도 올바른 판단을 내리는 것을 확인할 수 있었다.
Ⅳ. 결론 및 향후 연구
건설분야의 문제해결에 인공지능을 활용하기 위해 데이터셋과 하이퍼파라미터의 조정을 통해 해결법을 신속하게 찾는 것이 중요해지고 있다. 본 논문에서 학습에 영향을 미치는 요인으로서, 모델의 구조 외에 학습에 영향을 미치는 데이터셋의 유형 다양성, 학습주기 등을 변경하면서 정확도를 점검할 수 있는 일련의 절차를 제안하였다. 학습 결과는 균열 유무를 정확하게 판단하는지에 관한 것이다. 딥러닝 방법 중에서 상대적으로 구조가 간단함에도 불구하고 예측 정확도가 높게 도출된 VGG 16 모델을 참조하였다. 이 모델을 기반으로 상대적으로 간단한 구조의 모델을 구축하는 과정에서 데이터셋과 하이퍼파라미터의 조정을 통해 정확도와의 관계를 분석하였다.
이 균열 분류 방식은 현재의 점검 프로세스와 비교하였을 때에 시간, 인력, 경제성 측면에서 효율성을 달성할 수 있다. 딥러닝 기반의 실내 마감재 균열 디텍션을 진행하는 경우, 비전문가에 의해 수행될 수 있으며 모델의 구조 외에도 데이터셋과 하이퍼파라미터의 조정을 통해 적은 데이터셋을 통해서 인식 정확도를 향상시킬 수 있다.
이 딥러닝 모델에서 핵심은 예측에 대한 오류인데, 특히 균열이 비균열로 인식되는 경우의 비율이 중요하다. 본 연구에서 이 비율을 최소화하기 위해 딥러닝 변수들을 조율함으로써 정확도와 검증 정확도를 유사하게 조정하였다. 무엇보다 중요한 것은 학습하는 학습에 활용되는 이미지를 점검하는 것, 학습량, 학습주기에 대한 예측오류의 문제를 해결할 수 있었다. 다소 간단한 플라스틱 보드의 재료를 활용하였는데, 300-500개의 데이터셋을 통해서도 높은 예측정확도를 도출할 수 있었을 뿐 아니라 데이터셋과 다른 이미지에 대해서도 높은 정확도를 얻을 수 있었다.
추후의 연구는 두 가지로 진행될 예정이다. 최종 모델을 활용하여 훈련 – 예측을 3회 정도 재차 실행하였을 때 오차는 5%(85 ~90 %) 발생하였는데, 이를 일정하게 유지하는 방법을 필요로 한다. 이 밖에도 기존 안전점검 사례를 조사함으로써 딥러닝 기반의 균열/비균열 분류방법이 프로세스 내에 적용되었을 때, 인력 투입 및 경제적 측면에서 효율성을 비교 분석할 필요가 있다.
Acknowledgments
본 연구는 국토교통부/국토교통과학기술진흥원의 지원으로 수행되었음(과제번호 RS-2022-00143782).
This work is supported by the Korea Agency for Infrastructure Technology Advancement(KAIA) grant funded by the Ministry of Land, Infrastructure and Transport (Grant RS-2022-00143782).
References
- Technology Policy and Construction Policy Bureau, Promotion of 「Smart Construction Activation Plan S-Construction 2030 (in Korean), 2022.07.19., 2021.
- Jaeyong, S., Construction industry competes to preoccupy data centers...‘Average annual growth of 16%, eyes on blue ocean’(in Korean), Press of New daily, 2022.10.11., https://biz.newdaily.co.kr/site/data/html/2022/10/11/2022101100083.html, , 2022.
- Ministry of Health and Welfare, Changes made with the people, a government that fulfills its responsibility to the end (in Korean), 2021.12.28., 2022.
- Korea Authority of Land & Infrastructure Safety, “Establishment of artificial intelligence deep learning-based bridge maintenance decision-making system(in Korean)”, Press of New daily, 2019.
- Yu, T. “Hyper-parameter optimization: a review of algorithms and applications”, arXiv preprint arXiv:2003.05689, , 2020.
- Shim, Y. J., “AI Based Construction Technology and Research Strategy”, Land and Housing Institute, 2020.
- Jung J. W. and Gu, T. and Jang, W. J., Google deep learning framework, KwangMunKak, 2019.
- Lee, J. E. “Hyperparameter Optimization for Image Classification in Convolutional Neural Network”, The Journal of Korea Institute of Convergence Signal Processing, vol.21, no.3, pp. 148-153, 2020.
- Pyo. T. J. and Ryu, J. M., Accident about the collapse of the outer wall, https://news.chosun.com/site/data/html_dir/2019/05/23/2019052300252.html, , cited in 2019. 5. 23, 2019.
- Ministry of Land, Infrastructure and Transport, The statute will be amended regarding exterior wall finishing materials (in Korean), http://www.korea.kr/news/pressReleaseView.do?newsId=156332994, , cited in 2019. 5. 23, 2019.
저자소개

2013년 : 성균관대학교 대학원 (건축학석사-디지털컴퓨팅, BIM)
2018년 : 성균관대학교 대학원 (건축학박사-디지털컴퓨팅, BIM)
2018년~2019년: 성균관대학교 박사후연구원
2019년~현 재: 한국건설기술연구원 박사후연구원
※관심분야 : 딥러닝, 해상도변환, 공간정보, 건설절차, 블록체인, BIM 전략 등

2002년 : 인하대학교 대학원 (공학석사-지리정보)
2012년 : 인하대학교 대학원 (공학박사수료-지리정보)
2002년~현 재: 한국건설기술연구원 연구위원
※관심분야 : 건설IT융합, 건설메타버스, 시설물안전, 재난관리 등

1998년 : 연세대학교 대학원 (공학석사)
2006년 : Purdue University (공학박사-Feature Extraction from Sensors)
2007년~2012년: 삼성SDS
2012년~현 재: 한국건설기술연구원
※관심분야 : Feature Extraction, Photogrammetry, Computer Vision, UAV/UAM Air Roads 등