한국어 음운의 음성적 특징과 대중음악 가사의 연관성
Copyright ⓒ 2020 The Digital Contents Society
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-CommercialLicense(http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.

초록
본 논문은 가창 시 나타나는 한국어 음운의 음성적 특징과 대중음악 가사의 연관성을 실증하기 위한 연구이다. 수백 년에 걸쳐 다양한 이론이 정립되고 발전한 작곡에 비해 작사의 경우는 체계적인 연구가 매우 미비하다. 작사와 작곡은 각기 고유의 예술적 감각을 기반으로 하는 창작활동이지만 최종적으로 소리를 매개로 한다는 공통점이 있다. 따라서 본 연구는 작사 역시도 음향적 특징을 통해 체계화, 이론화가 가능할 것이라는 가설에서부터 시작되었다. 연구 결과 작사 과정에서 반영되는 음운의 다양한 음성적 특징을 도출할 수 있었다. 이와 같은 연구를 통해 정립한 기준을 바탕으로 기존 대중음악의 가사를 분석한 결과 그동안 규명하기 어려웠던 음운의 음성적 특징과 가사의 연관성에 대한 다양한 원리와 효과를 설명할 수 있었다. 본 연구의 내용을 통해 작사가들은 완성도 높은 가사를 작성하는데 참고 가능한 음운의 음성적 특징을 학습할 수 있게 될 것이다.
Abstract
The purpose of this study is to demonstrate the relationship between vocal features of Korean phonology and popular music lyrics. While various theories have been established and developed over hundreds of years in the case of composition, systematic research is very lacking for writing lyrics. Writing and composition are creative activities based on their own artistic senses, but the common theme is that they both use sound as a medium. Therefore, this study started from the hypothesis that writing lyrics could be systematized and theorized through vocal features. As a result, we were able to derive various vocal features of phonology applied in the writing process. Applying the above study results, we analyzed the lyrics and pronunciation of existing popular music and found various principles and effects on the connection between the vocal features of sound and the lyrics and pronunciation of sound that had been difficult to find. Through the contents of this study, lyricists will be able to learn the vocal features of the phonological notes that can be used to write high-quality lyrics.
Keywords:
Korean phonology, Lyrics, Popular music, Practical music, Song writing키워드:
가사, 대중음악, 실용음악, 작사, 한국어음운Ⅰ. 서 론
노래는 악기만을 이용한 음악과 달리 가사를 사용하기 때문에 음악에 담긴 메시지를 언어를 통해 직접적으로 전달할 수 있고 청자의 공감을 극대화할 수 있다는 장점이 있다. 또한 가수는 화면과 무대 전면에서 적극적으로 노출되며 이들이 부르는 노래는 악기연주와 달리 대중이 쉽게 따라 부를 수 있다. 따라서 청자의 기호와 공감을 기반으로 한 대중음악의 소비는 노래 음악을 중심으로 이뤄지고 있으며 그중 가사는 대중음악의 핵심 요소로 꼽을 수 있다.
성서의 문장에 선율을 붙인 성가나 음유시인에 의해 불리던 세속 음악[1] 등 과거의 노래와 다르게 현재의 대중음악 작사 과정은 선율 작곡 이후 가사를 붙이는 방식이 일반적이다. 작사가 심현보는 그의 저서에서 곡이 먼저인가, 가사가 먼저인가에 대한 물음에 다음과 같이 답하고 있다. “결론부터 이야기하자면 98퍼센트 이상 곡이 먼저다. 나머지 2퍼센트에 해당하는 부분도 대부분 싱어송라이터의 경우에만 해당한다고 볼 수 있으니, 상업 작사가의 경우라면 거의 100퍼센트 곡이 먼저라는 이야기가 된다[2].” 비단 심현보뿐 아니라 대중음악 작사가가 본인의 경험을 작성한 저서들을 확인해 보면 데모곡에 담긴 가이드보컬의 노래에 맞춰 작사하는 경우가 대부분이다. 이들이 주장하는 바가 개인의 주관적인 경험과 의견이라는 점을 감안하더라도 현업에서 왕성하게 활동하는 대중음악 작사가들의 공통된 견해라는 점으로 미루어볼 때, 대중음악 제작에서 곡과 가사의 선후 관계는 비교적 명확하게 결론지을 수 있다. 즉, 현시대에는 이미 완성된 가사에 어울리는 선율을 만드는 작업 방식이 아닌, 정해진 선율에 어울리는 가사를 작사하는 작업 방식을 사용하고 있다. 따라서 대부분의 작사가들은 작사 과정을 감각에 의존한다. 물론 고음 가창 시 유리한 발음 정도는 다수의 작사가들이 인지하고 있으며 개개인이 쌓아온 경험에 의해 터득한 작사 노하우들이 있기도 하다. 작사가 김이나는 “발라드에서는 튀는 발음을 최소화할수록 좋다.”, “고음을 길게 끄는 부분에서는 받침이 없을수록 좋고, ‘아’나 ‘어’등 목을 최대한 열 수 있는 발음을 넣어야 한다.”, “센 발음을 배치하기 위해 선택한 된소리나 파열음, 파찰음이 포함된 단어들이다”라고 했다[3]. 이처럼 작사가들은 개인의 경험이나 타인의 작품 혹은 작업과정을 통해 정리한 일종의 주관적 작사법을 바탕으로 작업에 임한다. 마치 음악가가 많은 곡을 분석하거나 작곡하며 터득한 유기적인 화성진행을 정리해 작곡 과정에 사용하는 것과 유사한 방식이다. 하지만 작곡의 경우 수백 년에 걸쳐 화성학, 대위법, 선율 작곡법 등 다양한 이론이 연구를 통해 정립된 반면, 작사에 대한 체계적인 연구와 이론은 매우 미비한 현실이다. 두 가지 창작활동은 고유의 예술적 감각을 기반으로 만들어지지만 최종적으로 소리를 매개로 한다는 공통점이 있기에 작사 또한 작곡과 마찬가지로 음향적 원리와 특징을 통해 이론화 할 수 있는 가능성이 있다고 판단된다.
따라서 본 논문은 가창 시 한국어 음운의 음성적 특징을 과학적으로 연구하여 대중음악 가사와의 상호 연관성을 밝히고자 한다. 이를 통해 감각이나 주관적인 경험에 의존하던 기존의 작사 방식에 이론적인 요소를 더하여 보다 효과적인 작사 작업과 가사 분석이 가능해지는 한편, 본능적으로 인지할 수는 있으나 구체적으로 설명하기 어려웠던, 가사와 선율의 청각적 조화를 객관적으로 분석할 수 있을 것이다.
Ⅱ. 연구 설계
2-1 연구 도구
가창 시 한국어 음운에 따른 음성적 특징을 연구하기 위해 대중음악 녹음에서 빈도 높게 사용되는 단일지향성(cardioid)으로 설정된 노이만(Neumann) U87 Ai 콘덴서 마이크(condenser microphone)로 음원 표본을 녹음하였다. 녹음한 음원 표본은 스펙트럼 애널라이저(spectrum analyzer) 플러그인인 웨이브즈(Waves)의 PAZ Frequency와 아이조톱(Izotope) Ozone5의 Meter Bridge 중 스펙트로그램(spectrogram)으로 분석하였다. 녹음은 상업 음반이 녹음되는 환경에 준하는 전문 레코딩 스튜디오에서 진행하였으며 녹음 시 사용한 외장 음향 장치는 튜브테크(Tube-Tech)의 컴프레서(compressor) CL 1B와 그레이스 디자인(Grace design)의 오디오인터페이스(audio interface) m802이다. 레코딩 시스템은 상업 음반 녹음 시 빈도 높게 사용하는 아비드(Avid) Pro Tools HD의 버전12와 192io시스템이다. 보컬 트랙에 적용한 소프트웨어 플러그인은 웨이브즈의 SSL Channel mono이며 프리셋(preset) 중 Lead Vox를 선택하여 인서트(insert)로 적용했다.
2-2 연구 방법
가창 시 한국어 음운의 특징을 확인하기 위해 녹음에 참여한 가창자는 보컬 트레이닝을 전문적으로 받은 실용음악과 보컬 전공생들로 구성했다. 음성적 차이가 큰 남성과 여성의 독립적인 분석을 위해 남성 집단과 여성 집단으로 나누어 실험을 진행했으며 분석 결과의 신뢰도를 높이기 위해 남녀 각 3명씩 총 6명이 가창하여 제작한 음원 표본을 대상으로 했다. 녹음 시에는 마이크를 가창자의 입으로부터 약 20∼30 cm 떨어뜨려 마이크 스탠드에 설치를 하고 그 사이에 팝필터(pop filter)를 설치하였다. 자음과 모음에 대한 모든 가창은 연구의 수월성과 남녀의 음역을 고려하여 남성 보컬 곡과 여성 보컬 곡에서 일반적으로 사용하는 음역 내의 음 중 6개의 음을 선정하여 사용했다. 6개의 음은 남성의 음역에 해당하는 B2∼G4음과 여성의 음역에 해당하는 G3∼D4음 중 남녀 각각 B2, D3, G3, B3, D4, G4의 6개 음과, G3, B3, D4, G4, B4, D5의 6개 음이다. 배지나는 국내외 주요 보컬 관련 이론서들의 내용을 확인한 뒤 남성의 음역을 A2∼G4, 여성의 음역을 F3∼D5로 설정하였으며[4] 실제 대중음악의 선율도 위의 음들을 주요 음역으로 사용한다.
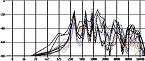
19개의 자음은 발화 시간이 지나치게 짧아 모음 없이는 온전하게 발음하는 것이 불가능하기 때문에 단모음 중 /ㅏ, ㅣ, ㅜ/와 조합하여 녹음을 진행했다. 10개의 단모음 중 /ㅏ, ㅣ, ㅜ/를 선택한 이유는 아래 그림 1에서처럼 단모음들 중 모음 삼각도의 각 꼭짓점에 해당하여 발음 차이가 가장 크기 때문이다.

Korean Single Vowel-triangle[5]
녹음 받은 음원 표본은 PAZ Frequency와 Ozone5 등으로 분석했다. 다만 시간의 흐름에 따라 시시각각 변화하는 스펙트럼을 모두 담을 수 없고 지면의 면적을 지나치게 점유하기 때문에 가창 시작 직후부터 40 ms(0.04초)씩 4등분으로 분절하여 각 단계별로 주파수 별 가장 큰 음압인 피크레벨(peak level)을 기록하고 분석했다. 단, 4단계로 확인이 부족한 일부 음원은 6단계로 확장하여 분석했고 더욱 세부적인 확인이 필요한 경우는 10 ms씩 추가 분절하여 총 1,700개의 가창 음원 표본을 분석했다.
본 연구의 분석 대상 곡은 2019년 1월부터 8월까지 가온차트의 월간 디지털 차트 1위부터 10위에 랭크된 곡 총 80곡을 1차적으로 선별하였으며, 일반화 가능하고 유의미한 연구결과를 위해 표본이 가장 많은 전형적인 발라드 편곡의 19곡과 댄스 곡 9곡, 총 28곡을 최종 선별해 분석했다.
1차 선별된 80곡의 장르별 곡의 수는 중복 내역과 연구 대상이 아닌 외국 곡을 제외하고 발라드 22곡, 댄스 9곡, 랩/힙합 6곡, 록/메탈 4곡, R&B/소울 3곡, 포크/블루스 2곡이었으나 발라드와 댄스 곡을 제외하고는 장르별 표본이 부족해 연구 결과를 일반화하기에는 무리가 따랐다. 따라서 본 연구에서는 표본이 가장 많은 발 라드 장르와 댄스 장르의 곡을 대상으로 분석했으며, 그중 발라드 22곡의 경우 장르적, 음악적인 동질성을 확보하기 위해, 벌스 파트에서부터 곡 전체적으로 드럼 등의 타악기가 포함되어 있거나 한 옥타브 이내의 좁은 음역을 사용하는 곡을 제외한 전형적 편곡의 발라드 19곡을 선별했다. 댄스 곡의 경우는 영어 가사의 비율이 타 장르에 비해 높아 음운의 청각적 강도 사용 비율을 생략한 곡들이 다수 있었지만 음운의 사용 방식의 공통점과 발음 방식에서 나타난 특징 등 유의미한 연구결과가 도출되었기에 연구에 포함했다.
Ⅲ. 가창 시 한국어 음운의 음성적 특징
3-1 자음의 음성적 특징
자음은 입이나 혀, 목 등을 사용해 폐에서 나오는 공기의 흐름을 막거나 흐름에 장애를 주는 방식으로 조음하는 소리이다. 자음은 조음 방식과 조음 위치에 따라 구분할 수 있지만, 본 논문에서는 그중 음성적 특징의 연관성이 분명한 조음 방식에 따른 분류로 구분지어 연구했다. 자음의 분류별 명칭은 일반적으로 사용되는 명칭으로 기재했으며 이진호의 책 등을 참조하였다[6].
첫째, 파열음의 개방 후 무성기간은 전반적으로 매우 짧으며 그중 경음이 가장 짧고 유기음이 가장 길다. 위의 표 1은 실험 대상 전체의 파열음 ‘바, 파, 빠’의 개방 후 무성기간을 기록한 것이다. 평균적으로 ‘바’ 27.7 ms, ‘파’ 32.7 ms, ‘빠’ 10.8 ms의 시간이 도출되었다. 가창의 경우가 아닌 일상 언어의 경우도 위 결과와 유사하다. 김신우는 그의 논문에서 국어의 개방 후 무성기간은 /ㅂ, ㄷ, ㄱ/ 약 35 ms, /ㅍ, ㅌ. ㅋ/ 약 93 ms, /ㅃ, ㄸ, ㄲ/ 약 12 ms라고 말했다[7]. 즉, 가창 시와 일상 언어 발음 시 모두 개방 후 무성기간의 길이는 유성음, 평음, 경음 순으로 길었다.

VOT(Voice-onset time) of plosive
둘째, 파열음은 마이크를 통해 서브베이스(0∼60 Hz)의 음압을 순간적으로 높인다. 파열음 발화 시 입을 막아 구강에서 체류하고 있던 공기가 순간적으로 분출되면서 마이크의 진동판을 흔들게 되는데 이때 진동 속도가 서브베이스에 해당하여 디지털 오디오에 기록된다. 이는 가창하는 기음의 주파수보다도 낮은 음역이고 인간이 부를 수 있는 최저음보다도 낮은 주파수에 해당하지만 마이크를 통해 음압이 분명하게 입력된다.
셋째, 파열음은 엔벨로프(envelope)의 어택타임이 매우 짧아 두드려서 소리를 내는 타악기와 유사한 성질이 있다. 다만 개방 후 무성기간 역시 짧기 때문에 일반적인 타악기와는 달리 빠른 뮤팅(muting)이 동반되는 악기, 즉 대중음악에서 사용되는 드럼과 유사하다.
넷째, 서브베이스의 음압은 유기음이 가장 강하다. 입 바로 앞에 종이를 대고 파열음을 발음해보면 ‘파’를 발음할 때 종이가 가장 많이 흔들리고 ‘바’를 발음할 때 조금 흔들리며, ‘빠’를 발음할 때는 종이가 흔들리지 않는다[8]. 음압은 마이크의 진동판이 물리적으로 흔들리는 진폭에 의해 결정되기 때문에 아래 표 2처럼 공기가 가장 큰 힘으로 분출되는 유기음에서 가장 높았다.
Sub-bass frequency sound pressure of plosive
첫째, 마찰음의 지속 시간은 길다. 특히 마찰음 중 /ㅅ/과 /ㅆ/의 개방 후 무성기간은 자음 중 가장 길다. 앞서 분석한 파열음의 개방 후 무성기간은 평균 10.8∼32.7 ms에 불과했지만 마찰음의 개방 후 무성기간은 위 표3의 결과처럼 ‘사, 하, 싸’ 음원의 경우 평균으로 /ㅅ/ 142.8 ms, /ㅎ/ 68.4 ms, /ㅆ/ 181.4 ms에 달했다.
VOT of fricative
둘째, 마찰음은 /ㅅ, ㅆ/의 음성적 특징과 /ㅎ/의 음성적 특징은 큰 차이가 있다. /ㅅ, ㅆ/은 혀끝을 윗니 뒤쪽에 가까이 접근시켜 조음하는 치조음에 해당하고 /ㅎ/은 성대의 막음이나 마찰을 수반하는 후음에 해당하기 때문에 그 차이가 뚜렷한 것이다[8].
셋째, 마찰음은 메탈 쉐이커(shaker)와 카바사(cabasa) 등의 악기를 여리게 연주했을 때와 음향적 특징이 유사하다. 이들 악기는 마찰로 인해 소리가 생성되어, 타격이라는 행위로 연주하는 일반적인 타악기들과 비교해 어택타임이 비교적 느리다. 또한 악기 재질이 금속 위주이기 때문에 소리의 주파수가 하이 구간에 주로 분포하고 있어 /ㅅ, ㅆ/과 그 음향적 특징이 매우 유사하다.
넷째, 마찰음 중 /ㅅ, ㅆ/은 개방 후 무성기간이 길기 때문에 다른 자음에 비해 가창 시 소요되는 시간이 오래 걸린다. 이는 지나치게 짧은 음의 길이에서는 /ㅅ, ㅆ/을 정확하게 가창하기가 어렵다는 의미가 된다. 예를 들어 bpm60의 곡에서 4분 음표(♩)의 길이는 1초 즉, 1,000 ms이고, 8분 음표(♪)는 500 ms, 16분 음표(
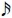 )는 250 ms, 32분 음표(
)는 250 ms, 32분 음표(
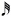 )는 125 ms이다. 또한 bpm120의 곡에서 4분 음표의 길이는 500 ms, 8분 음표는 250 ms, 16분 음표는 125 ms이다. 즉, bpm60의 32분 음표나 bpm120의 16분 음표 등 짧은 음 길이에서는 /ㅅ, ㅆ/의 자음 발음을 하는데도 충분하지 않은 시간이기 때문에 모음까지 발음하기 전에 해당 음의 길이가 끝날 수 있다. 게다가 여기에 받침까지 있을 경우라면 더더욱 음의 길이를 지키기 어렵거나 온전한 발음을 할 수 없게 된다. 때문에 가창자는 /ㅅ, ㅆ/의 자음을 사용한 가사를 가창할 경우 지정된 박자보다 먼저 발음하는 특징을 보였다.
)는 125 ms이다. 또한 bpm120의 곡에서 4분 음표의 길이는 500 ms, 8분 음표는 250 ms, 16분 음표는 125 ms이다. 즉, bpm60의 32분 음표나 bpm120의 16분 음표 등 짧은 음 길이에서는 /ㅅ, ㅆ/의 자음 발음을 하는데도 충분하지 않은 시간이기 때문에 모음까지 발음하기 전에 해당 음의 길이가 끝날 수 있다. 게다가 여기에 받침까지 있을 경우라면 더더욱 음의 길이를 지키기 어렵거나 온전한 발음을 할 수 없게 된다. 때문에 가창자는 /ㅅ, ㅆ/의 자음을 사용한 가사를 가창할 경우 지정된 박자보다 먼저 발음하는 특징을 보였다.
다섯째, 마찰음 중 하이(6,000∼20,000 Hz) 주파수 음압이 증폭되는 /ㅅ, ㅆ/은 자음 중에서도 소음성(騷音性, strident)이 매우 강한 음들이다[9]. 이들의 주파수는 약 8,000∼13,000 Hz의 하이에 해당하는 매우 높은 주파수를 중심으로 분포하고 있다. 이는 사람의 성대에서 낼 수 있는 최대 진동수는 물론이고 피아노의 가장 높은 음인 C8의 기음 4,186 Hz보다도 두 배 이상 높은 주파수에 해당한다. 즉, 마찰음은 매우 높은 주파수 음압이 증폭되기 때문에 다른 소리들에 비해 가볍고 밝고 선명한 음성적 특징을 가지고 있다. 이는 마치 그릇이나 칠판이 긁히는 소리가 사람의 귀에 매우 자극적으로 들리는 것과 마찬가지 효과이다. 다만 /ㅅ, ㅆ/의 자음이 모음 /ㅣ/와 조합될 경우는 약 4,000∼7,000 Hz 중심으로 음압이 증가하는 현상을 보였는데 이는 /ㅣ/와 조합해 발음할 경우 치조가 아닌 경구개 부근에서 마찰이 일어나는 까닭이었다. 특히 국제 음성 기호(International Phonetic Alphabet)로 표기할 경우 대부분의 /ㅅ/이 /s/로 표기되고 /ㅆ/이 /s'/로 표기되는 반면, 모음 /ㅣ/나 /y/와 조합한 /ㅅ, ㅆ/의 경우는 /ʃ, ʃ'/로 그 표기 방법조차 다를 정도로 차이가 나는 음성적 특징을 가지고 있다. 이러한 특징은 ‘싸, 씨, 쑤,’ 음원 스펙트럼을 분석한 다음 표 4를 통해 확인할 수 있다.
‘싸, 씨, 쑤’ spectrum 40∼80 ms
첫째, 파찰음은 파열음과 마찰음의 특징을 동시에 가지고 있는 만큼 음성적인 특징도 파열음과 마찰음의 특징이 섞여있다. 파찰음은 발성 초기에 하이 주파수 음압의 상승이 두드러지며 마찰음의 음성적 특징을 보이다가 이후 증폭되었던 하이 주파수 음압이 빠르게 감소하며 서브베이스 주파수 음압이 순간적으로 증가하는 음성적 특징을 보였다. 이는 파찰음이 초기에 파열음의 특징을, 이후에는 마찰음의 특징을 보인다고 하는 일반 음운학[6]과는 상이한 결과였다.
둘째, 파찰음은 파열음에서와 마찬가지로 개방 후 무성기간의 길이가 유기음인 /ㅊ/이 가장길고 경음인 /ㅉ/이 가장 짧았다. 그 이유는 파열음과 파찰음에서 대립하는 평음, 유기음, 경음의 삼지적 상관속[10]이며 모음의 성대 진동이 지연되는 시간이 성문의 크기와 개방 시점에 따라 달라진다.
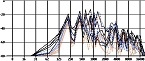
셋째, 파찰음에서 증폭되는 주파수 약 4,000∼9,000 Hz는 인간의 귀에 가장 민감하게 청취되는 주파수와 근접해있다. 아래 그림 2의 등청감곡선(equal loudness contour)에서 확인할 수 있듯 같은 음압이라면 인간의 귀에 가장 크게 인지되는 주파수는 약 4,000 Hz(4 kHz)를 중심으로 한다. 따라서 같은 음압이라면 다른 자음들에 비해 파찰음이 순간적으로 인간의 귀에 가장 선명하게 들릴 수 있는 가능성이 있다. 다만, 그 지속 시간이 마찰음 /ㅅ, ㅆ/에 비해 짧기 때문에 실제로는 마찰음 /ㅅ, ㅆ/이 약 8,000∼13,000 Hz 중심으로 증폭된다 할지라도 가장 선명하게 들릴 수 있는 가능성 역시 존재한다.

equal loudness contour[11]
첫째, 비음은 음성적 변화가 뚜렷하지 않고 하이 주파수 음압 증폭이 적어 그 존재감이 약하다. 마찰음과 파찰음의 소리가 선명하고 자극적으로 들리는 이유가 소음성이 강한 높은 주파수 음압의 증폭이라는 점에서, 하이나 하이미드(2,000∼6,000 Hz)에 해당하는 높은 주파수의 증폭이 발견하기 어려운 비음은 소음성이 낮다.
둘째, 비음은 파열음처럼 공기를 막았다가 터뜨리는 과정을 거치지만 코를 통해 공기를 배출하기 때문에 입으로 배출되는 공기의 압력이 파열음에 비해 현저하게 떨어진다. 따라서 파열음처럼 서브베이스 음압이 상승하는 경향이 있긴 하지만 그 정도가 미미하다.
유음은 공기를 막는 장애가 가장 적은 발화과정을 거치는 만큼 파열음 적인 특징인 서브베이스 음압의 증폭이 적었다. 또한 공기의 통로가 좁아지면서 생기는 하이, 하이미드 주파수 음악의 증폭 역시 적었다. 즉, 유음 역시 비음처럼 자음으로서의 존재감이 약하다고 판단할 수 있다.
3-2 모음의 음성적 특징
모음은 자음에 비해 발화시간이 길다. 특히 발성을 음표의 길이에 맞춰 유지해야하는 노래의 경우 일반적인 언어보다 모음의 길이가 훨씬 길다. 때문에 노래에서는 모음의 역할이 매우 중요하다고 볼 수 있다. 자음과 달리 모음은 발화 시 공기의 흐름에 방해가 적기 때문에 자음처럼 조음 위치나 조음 방식을 기준으로 분류하기 힘들다. 따라서 모음을 분류하는 기준은 자음과 다를 수밖에 없다.
일반적으로 모음은 혀의 위치와 입술 모양을 기준으로 구분한다. 혀의 위치에 따른 구분은 혀의 전후 위치에 따라 전설모음과 후설모음으로 구분할 수 있으며 혀의 높낮이에 따른 구분은 혀의 고저에 따라 폐모음(고모음), 반폐모음(중고모음), 반개모음(중저모음), 개모음(저모음)으로 구분할 수 있다. 입술 모양에 따른 구분은 입술을 동그랗게 오므리는 원순 모음과 입술을 오므리지 않는 평순 모음으로 구분할 수 있다.
첫째, 전설모음은 후설모음에 비해 선명하게 들린다. 앞의 표 5 중 전설모음 /ㅣ, ㅟ, ㅔ, ㅚ, ㅐ/와 후설모음 /ㅏ, ㅓ, ㅡ, ㅗ, ㅜ/의 스펙트럼을 비교해보면 전설모음이 후설모음에 비해 하이미드 주파수 음압이 높다는 것을 알 수 있다. 특히 전설모음은 후설모음보다 약 2,000∼4,000 Hz 부근의 음압이 현저하게 높다. 앞서 언급했듯 같은 음압이면 4,000 Hz 부근의 주파수가 인간에 귀에 가장 크게 들린다는 것을 감안할 때 전설모음이 후설모음에 비해 존재감 있게 들린다는 의미가 된다.
spectrum of front vowel and back vowel
둘째, 후설모음이 전설모음에 비해 질감이 어둡다. 후설모음의 하이미드 주파수 음압이 전설모음에 비해 낮기 때문에 고음역의 주파수 음압이 낮을수록 소리의 질감이 어두워지는 음향적 특성상 후설모음의 질감이 전설모음보다 어둡다는 것을 확인할 수 있다. 특히 후설모음 중 원순 모음인 /ㅗ, ㅜ/의 경우 그 정도가 확연하다. 아래 표 6은 G3음으로 남성1이 가창한 전설모음 /ㅣ, ㅟ, ㅔ, ㅚ, ㅐ/와 후설모음 /ㅏ, ㅓ, ㅡ, ㅗ, ㅜ/의 스펙트로그램을 비교한 표이다. 전설모음 중 /ㅣ, ㅟ/에서 약 400∼2,000 Hz 주파수의 음압이 현저하게 낮으며, 후설모음 중 /ㅗ, ㅜ/에서 1,000 Hz 이상의 음압이 매우 낮은 것을 확인할 수 있다.
spectrogram of front vowel and back vowel
한국어의 단모음은 혀의 높낮이에 따라 크게 폐모음, 반폐모음, 반개모음, 개모음으로 나뉜다. 각 음의 높이마다 최대한 동일한 음압으로 10개의 단모음을 불러 녹음한 뒤 음원 표본들의 주파수 별 피크레벨을 비교 분석했다. 효과적인 비교를 위해 6명의 가창자가 녹음한 모음 10개에 대해 개인 별 평균 음압을 도출한 뒤 모음 별로 평균과의 음압 차이를 작성하였다. 혀의 높낮이에 따라 폐모음, 반폐모음, 반개모음, 개모음으로 구분하여 분석한 모음의 음성적 특징을 정리해보면 앞의 표 7과 같다. 반폐모음인 /ㅗ/가 반개모음인 /ㅐ/보다 평균 순위가 미세하게 높은 점만 제외한다면 모음의 음압은 전반적으로 개모음, 반개모음, 반폐모음, 폐모음 순으로 높은 경향이 있다. 위와 같은 결과는 모음을 녹음한 아래 그림 3 음원의 파형으로도 쉽게 확인할 수 있다. 그림 3은 남성 G3음, 여성 D4음으로 가창한 단모음 10개의 음원 파형이다. 개모음, 반개모음, 반폐모음, 폐모음 순으로 파형의 진폭이 크다는 것을 쉽게 파악할 수 있다. 다만 가창자가 완벽하게 동일한 세기로 부르려고 노력하더라도 가창자에 따라, 혹은 같은 가창자라도 가창 시마다 음압은 오차가 있을 수 있기에 앞의 표 7에서 나열한 순서가 절대적인 것은 아니다. 하지만 수차례 실험을 거듭하고 여러 명의 표본으로 확인한 결과에서 나타난 일관된 경향에 의거하여 본 연구에서는 표 7을 기준으로 하여 모음의 강도를 분석했다.
vowels arranged in order of sound pressure

wave of vowel
Ⅳ. 대중음악 가사와의 연관성
4-1 청각적 강도와의 연관성
자음의 음성적 특징은 증폭 주파수와 증폭 정도, 증폭 시간을 기준으로 구분하여 정리할 수 있다. 또한 이들의 정보를 고려하여 자음이 가진 청각적 강도(intensity)를 도출했다. 위의 표 9는 자음의 청각적 강도를 도출한 표이다. 평가 기준은 증폭되는 주파수 대역, 해당 주파수 증폭 정도, 증폭 지속 시간이며, 청각적 강도를 구분지은 방법은 증폭 정도와 지속 시간을 반영하여 평가했다. 위와 같은 평가를 마친 결과 청각적 강도가 강한 자음부터 순서대로 나열하면 아래 표 10과 같다.
auditory intensity of consonants
auditory intensity sequence of consonants
(1) 파트별 청각적 강도
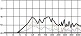
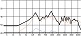
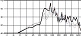
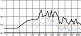
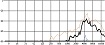
대중음악 중 발라드 장르의 경우 벌스 파트와 코러스 파트는 음악적 특징이 대조적이다. 서정적인 벌스 파트에서는 청각적 강도가 약한 자음을 위주로 사용하고 격정적인 코러스 파트에서는 청각적 강도가 강한 자음의 사용 비율을 높이면 그 대조성을 강조할 수 있다. 다음 그림 4는 <넘쳐흘러> 벌스 파트와 코러스 파트 각 음절 첫 자음의 청각적 강도를 표기한 그래프이다. 벌스 파트에서는 강도 ‘하’와 ‘중하’에 해당하는 자음이 각각 66.7%, 22.2%로 대부분의 비율을 점유해 전체적인 강도가 매우 약한 반면 코러스 파트에서는 음운의 강도가 전반적으로 강해졌다. 이러한 자음의 사용으로 인해 벌스 파트와 코러스 파트의 음향적 대조가 더욱 강조되는 효과가 나타났다. 이러한 현상은 분석 대상 전체 곡 중 강세 위치에서 음운의 청각적 강도 상승이 78%를 보인 것으로 볼 때 유의미한 현상을 사료된다.

<overflowing> auditory intensity of consonant by part※ Unit=%
(2) 선율의 청각적 강도
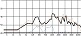
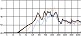
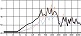
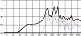
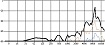
자음의 청각적 강도로 인해 선율의 리듬적 강세가 이동하는 경우도 쉽게 찾아볼 수 있다. 일반적으로 4분의 4박자 16비트(16beat) 음악은 위의 그림 5와 같은 강세를 사용하는 경향이 있다. 하지만 아래 그림 6에서처럼 <신용재>의 벌스 파트에서는 자음의 영향으로 인해 강세 위치가 업비트로 이동했다. ‘같은 옷을’은 문화어 발음법 제 10항에 의거하여 모음 앞에 있는 받침은 그 모음에 이어서 발음해야하므로 ‘가튼 오슬’로 발음된다. 같은 현상으로 ‘옷이라서’의 ‘옷이’도 ‘오시’로 발음된다. 또한 ‘함께 입던’의 ‘입던’은 받침 /ㄱ(ㄲ, ㅋ, ㄳ, ㄺ), ㄷ(ㅅ, ㅆ, ㅈ, ㅊ, ㅌ), ㅂ(ㅍ, ㄼ, ㄿ, ㅄ)/ 뒤에 연결되는 /ㄱ, ㄷ, ㅂ, ㅅ, ㅈ/이 된소리로 발음된다는 표준 발음법 제 23항에 의거하여 ‘입떤’으로 발음된다. 결론적으로 위의 가사는 ‘가튼 오슬’, ‘함께 입떤 오시라서 혹시’로 발음되어 가창 시 청각적 강도가 높은 자음이 배치된 업비트에 강세가 위치한다. 이러한 강세의 이동은 선율이 가진 리듬에 변화를 주는데 효과적인 도구가 된다.

general 16-bit rhythm stress

strength of the <Shin Yong-Jae> melody due to the effect of consonants
모음은 혀의 전후 위치에 따른 음성적 특징과 혀의 높낮이에 따른 음성적 특징으로 나눠 연구하였다. 혀의 전후 위치에 따라서는 전설모음에 가까워질수록 고음역 주파수가 강조되고, 후설모음에 가까워질수록 저음역 주파수가 강조된다는 점을 알 수 있었다. 또한 혀의 높낮이에 따라서는 혀의 위치가 낮아 입이 벌어진 크기가 커질수록 이에 비례해 음압이 커지는 경향도 확인할 수 있었다. 위의 결과를 바탕으로 모음의 음성적 특징은 고음역 주파수 증폭과 전체 음압의 크기를 기준으로 정리할 수 있었으며, 이들의 정보를 고려하여 모음이 가진 청각적 강도를 도출하였다. 앞의 표 11은 모음의 청각적 강도를 도출한 표이다. 청각적 강도를 구분하기 위한 평가 기준은 전체 음압과 고음역 주파수 음압의 합이며, 위와 같은 평가를 마친 결과 청각적 강도가 강한 모음부터 순서대로 나열하면 아래 표 12와 같다.
auditory intensity of vowels
auditory intensity sequence of vowels
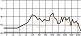
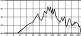
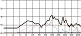
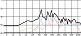
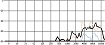
자음에서와 마찬가지로 서정적인 벌스 파트에서는 청각적 강도가 약한 모음을 위주로 사용하고 격정적인 코러스 파트에서는 청각적 강도가 강한 모음의 사용 비율을 높이면 대조성을 강조시킬 수 있다. 다음 그림 7은 <그대라는 시> 벌스 파트 각 음절 첫 모음의 청각적 강도를 표기한 그래프이다. 벌스 파트에서는 강도 ‘하’에 해당하는 모음의 사용 빈도가 46.2%로 가장 높은 반면, 코러스 파트에서는 강도 ‘상’에 해당하는 모음의 사용 빈도가 가장 높은 40%로 상반된 결과를 보였다. 벌스 파트 대비 코러스 파트 모음의 청각적 강도가 상승하는 경향은 분석 곡 전체의 74%를 차지하여 유의미한 현상으로 판단 할 수 있다.

<a poem called You> auditory intensity of consonant by part※ Unit=%
4-2 조음 방식과의 연관성
(1) 파열음의 조음 방식
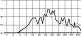
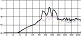
자음 중 파열음의 경우 조음점이 맞닿아 소리의 단절을 야기하기 때문에 음의 길이가 짧아지게 된다. 이는 악보 상 같은 음 길이의 선율이 가창 시에는 음운의 특징에 따라 상이할 수 있다는 의미이다. 위의 그림 8은 <180도>의 원곡 음원에서 코러스 파트 중 ‘백팔십도 달라진 너’에 해당하는 마디의 보컬 음원을 추출한 파형이다. 붉은색 점선으로 표시한 한 칸이 8분 음표에 해당한다. 파형을 통해 확인 가능하듯 ‘백’과 ‘십’에 해당하는 음운에서 받침의 영향으로 음의 길이가 악보상의 길이보다 짧아졌다. 이는 파열음 받침 /ㄱ, ㄷ. ㅂ/이 붙게 되면 조음체가 맞닿아 소리를 단절시키기 때문에 /ㄱ/과 /ㅂ/ 받침이 붙는 ‘백’과 ‘십’의 경우 그 영향으로 음의 길이가 단축되는 것이다. 게다가 각각 다음 음운인 ‘파’의 /ㅍ/, ‘또’의 /ㄸ/이 파열음이기 때문에 소리의 단절 현상이 더욱 두드러진다. 이를 악보로 표기해보면 다음 그림 9와 같이 표기할 수 있다. 그림 9에서 위의 마디는 일반적인 악보로 표기된 선율이며 아래 마디는 실제 가수가 가창한 음원을 채보한 선율이다. 제 3박에서부터 제 4박의 ‘달라진 너’에 해당하는 음은 이어 발음하기 용이한 음운이기 때문에 소리가 연결되어 있지만 제 1박부터 제 2박의 ‘백팔십도’는 유성음 /ㄹ/ 받침을 사용하는 ‘팔’을 제외하고 모두 음운의 음성적 특징으로 인해 음의 길이가 짧아졌다. ‘도’의 경우는 받침이 없음에도 약 32분 쉼표 정도 소리의 단절이 생겼는데 그 이유는 다음 음절 ‘달’의 첫 음운에서 파열음을 사용하여 조음점이 맞닿아 ‘도’와 ‘달’ 사이에 소리가 일시적으로 단절되었기 때문이다. 위와 같은 현상으로 인해 최고음에 해당하는 D5음, 8분 음표 길이의 네 차례 단순 반복되는 해당 선율이 음운의 특징으로 각각 길이가 다르게 가창되어 단순한 리듬 패턴에 변화를 더했으며, 파열음 받침을 사용한 급격한 음의 단절을 효과적으로 배치해 스타카토 주법과 유사하게 원음의 길이보다 짧게 끊어서 가창하도록 했다. 이와 같이 파열음 자음과 받침 사용은 음성적 특성상 분석 대상의 모든 곡에서 리듬적인 요소를 강조한다.

part of the vocal wave in the <180°> chorus part

change in the length of a note in <180°> due to the effect of a plosive
(2) 유성음의 조음 방식
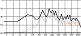
유성음에 해당하는 비음 /ㅁ, ㄴ, ㅇ/과 유음 /ㄹ/은 조음체가 맞닿더라도 각각 코와 혀 측면으로 공기를 흘려 소리를 지속시킬 수 있다. 따라서 유성음 자음으로 시작하는 음절은 선행 음절에서부터 소리의 단절 없이 연속적으로 발음 가능하다. 아래 그림 10처럼 <MILLIONS>의 코러스 파트 등에서 유성음 자음을 통해 소리의 지속성을 높였으며, 소리의 지속적인 연결을 통해 음절들이 자연스럽게 연결되고 음압의 유지에도 유리한 것을 확인할 수 있었다.

part of the vocal wave in the <MILLIONS> chorus part
(3) 마찰음과 파찰음의 조음 방식
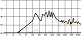
마찰음이나 파찰음의 경우 개방 후 무성기간이 길어 해당 음표의 시작점보다 앞서 발음이 시작된다는 특징이 있다. 다음 그림 11은 <벌써 12시> 원곡에서 추출한 벌스 파트 보컬 파형 일부이다. bpm 102의 <벌써 12시>에서 16분 음표의 길이는 147.1 ms에 불과하다. 따라서 ‘아쉬워 벌써 열두시’의 가사 중 ‘쉬’와 ‘써’의 음절이 발음되는 길이는 /ㅅ, ㅆ/이 자음을 포함하기 때문에 이들이 할당된 16분 음표 길이 이내에 온전히 발음하기가 매우 어렵다. 때문에 ‘워’, ‘벌’, ‘열’ 음절은 정박에서 가창이 시작된 것과 달리 노란색으로 표시한 /ㅅ/과 /ㅆ/은 지정된 박자보다 일찍 가창되었으며, 할당된 16분 음표 길이보다 ‘쉬’와 ‘써’ 음절이 실제로 발음된 길이가 더 긴 것을 확인할 수 있다. 이와 같이 개방 후 무성기간이 긴 자음은 그 조음 방식의 특성상 분석 대상의 모든 곡에서 지정 박자 이전에 발음이 시작되었다.

part of the vocal wave in the <It's already 12 o'clock> verse part
한국어 특성 상 발화 시 모음은 자음에 비해 길이가 월등하게 길다. 특히나 일정한 음의 길이를 유지해야하는 노래의 특성상 가창의 대부분을 차지하는 것은 모음이다. 이때 조음 방식의 특징에 따라 고음 발성에 용이한 음운과 어려운 모음이 있으며 작사 과정에서 이를 고려한다면 가창자가 보다 수월하게 노래할 수 있도록 도울 수 있다. 아래 표 13은 배지나의 논문에서 고음 발성에 용이한 모음과 어려운 모음을 정리한 것이다.
easy and difficult vowels for high-pitched vocalization
Ⅴ. 결론 및 시사점
본 논문은 한국어 음운의 음성적 특징과 대중음악 가사의 연관성을 객관적이고 과학적인 방법으로 연구하였다. 가사는 단순한 문장이 아닌 궁극적으로 가창을 목적으로 한 문학이기 때문에 음운의 음성적 특징을 면밀하게 파악하고 이를 효과적으로 사용할 수 있는 능력을 체득한다면 창작활동에 있어 매우 효과적인 도구로 사용할 수 있을 것이다. 물론 인간은 선험적으로 아름다운 소리와 조화롭지 못한 소리를 구분해낼 수 있는 능력이 있다. 따라서 작사 과정에서 선율에 맞춰 작성한 가사를 직접 가창하며 만족스러운 문장, 조화로운 소리가 될 때까지 수정을 거듭하며 완성도를 높일 수도 있다. 마치 화성 이론을 배우지 않고도 피아노 건반을 하나 둘씩 더해 눌러보며 잘 어울리는 조합이 나올 때까지 반복하는 과정과 유사하다. 다만 화성 이론을 습득한 사람은 시행착오 없이 빠르고 효율적으로 원하는 소리의 조합을 만들 수 있다. 그 이론은 수백 년에 걸쳐 수많은 음악 이론가들이 연구하고 검증한 역사와 함께 발전했으며 하나의 학문으로 정립되었다. 하지만 작곡과 마찬가지로 소리를 매개로하는 예술 활동인 작사에 관해서는 유독 이론적, 학문적 연구가 미비하다.
국내외로 대중음악을 전문적으로 교육하는 고등교육기관들이 저마다 작곡, 연주, 가창, 음향, 컴퓨터음악, 뮤직비즈니스, 음악 교육학 등 다양한 분야에 대한 심도 있는 교육을 제공하고 이를 통해 더욱 발전된 이론들과 창작 활동이 가능해졌다. 그러나 작사만큼은 여전히 문학적인 접근법 위주로 교육이 이뤄지고 있으며 작사에 대한 음향학적, 음운론적 접근은 쉽게 찾아보기 힘들다. 게다가 마이크와 다양한 음향 장비를 이용한 소리의 가공이 대중음악에서 필수적으로 수반됨에도 이와 연계한 연구 역시 매우 미흡하다.
따라서 본 연구는 한국어 음운의 음성적 특징을 단순히 음성학적인 측면에서 머무르지 않고 실제 가창 시 나타나는 현상과 마이크, 프리앰프, 오디오 플러그인 등 음향 장치들을 통해 소리가 변조되어 실제 대중들이 듣게 되는 음원을 분석하기 위해 기존 대중음악이 제작되는 과정과 같은 방식으로 녹음 후 음원을 표본화 하여 분석했다. 그 결과 언어학, 음성학에서 연구되는 언어로서의 한국어 음운이 아닌 가창에서 나타나는 음운의 음성적 특징들을 데이터화 할 수 있었다. 또한 지금까지 가사를 분석하는 데에는 특별히 정해진 기준이나 이론이 없었기 때문에 가사를 이론적, 학문적으로 분석하려고 하더라도 그 접근이 용이하지 않았다. 따라서 본 연구에서는 다소 단순한 분류이지만 음운이 갖는 청각적 강도를 5단계로 나누어 기준을 정했고 이 기준을 바탕으로 일관적인 가사 분석을 할 수 있었다. 이는 주제, 감정, 시대적 영향, 사회적 영향 , 문학적, 문화적 분석 등을 중심으로 기존 대중음악 가사 연구가 이뤄진 것과 달리 과학적이고 객관적인 음성 분석을 바탕으로 한 연구의 초석이 되었다는 점에서 차별화 되었다.
궁극적으로 본 연구는 대중음악 작사나 가창 시 청각적으로 감지할 수 있는 음운의 음성적 특징을 스펙트럼과 스펙트로그램, 보컬 음원의 파형 등을 사용하여 시각적 정보로 제공했다는 점에서 의의가 있다. 이를 통해 가창 시 각 음운의 음향적 특징을 체계화할 수 있었으며 이를 바탕으로 한국어를 사용하는 대중음악 작사에 있어 선율과의 조화가 우수한 가사를 작사하는데 기여할 수 있을 것으로 전망한다.
Acknowledgments
본 연구는 주저자 이철희의 2020년도 박사학위논문 연구데이터를 활용하여 재구성하였음[12].
References
- H. J. Kim, The flow of Western music, Dosol, p.13, 2003.
- H. B. Shim, Lyricist's note, Salimbooks, p.52, 2017.
- E. N. Kim, Kim Yi-na's Method of Lyrics, Munhakdongne Publishing Group, pp.42-47, 2015.
- J. N. Bae, The study of connectivity between the principles of using phonemes and high note vocalization for pop music vocalists, Master thesis, Dongguk University Graduate School of Culture and Arts, Seoul, 2017.
- S. M. Hwang, H. K. Yun, and B. H. Song, “Speaker Adapted Real-time Dialogue Speech Recognition Considering Korean Vocal Sound System,” The Journal of Korea Institute of Information, Electronics, and Communication Technology, Vol. 6, No. 4, pp. 201-207, December 2013.
- J. H. Lee, Lecture on Korean phonology, Samkyung Media Group, pp.58-65, 2019.
-
C. W. Kim. “On the autonomy of the tensity feature in stop classification,” Word, Vol. 21, No. 3, pp. 339-359, 1965.
[https://doi.org/10.1080/00437956.1965.11435434]

- H. Y. Lee, Korean phonetics, Taehak Media Group, pp.47-48, 1996.
- J. H. Lee, Korean standard pronunciation and real pronunciation, Akanet, p.108, 2012.
- S. J. Kim, H. S. Cho, Y. M. Hwang, and K. C. Nam, “Japanese Speakers' Perception Errors of Korean Lenis, Aspirated, and Fortis Consonants,” Communication Sciences and Disorders, Vol. 7, No. 1, pp. 166-180, March 2002.
- C. H. Lee, S. K. Hong, “A study on the hearing characteristic based equalizer design for the elderly,” Journal of Digital Contents Society, Vol. 19, No. 4, pp. 779-787, April 2018.
- C. H. Lee, The vocal features of Korean phonemes and the correlation between pronunciation and lyrics of popular music when singing, Ph.D. dissertation, Kyunghee University Graduate School, Yongin, 2020.
저자소개

2009년 : 경희대학교 (음악학사)
2013년 : 경희대학교 아트퓨전디자인대학원 (음악학석사)
2013년 : 경희대학교 대학원 (예술학박사)
2017년~현 재: 백석예술대학교 실용음악과 겸임교수
2019년~현 재: 경희대학교 포스트모던음악학과 겸임교수
※관심분야:작곡, 뮤직테크놀로지, 음악교육, 예술학 등

1997년 : 전남대학교 (음악학사)
2000년 : 캘리포니아주립대학교(LA) (실용음악석사)
2001년 : 서던캘리포니아대학교 (고급대학원과정)
2020년 : 단국대학교 대학원 (문화예술학박사 수료)
2004년~현 재: 경희대학교 포스트모던음악학과 교수
※관심분야:미디어음악, 실용음악, 예술교육, 문화정책 등