D-NeRF와 4DGS 촬영을 위한 인조데이터 기반 카메라와 촬영 환경 세팅 연구
Copyright ⓒ 2025 The Digital Contents Society
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-CommercialLicense(http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.

초록
NeRF(Neural Radiance Fields)와 3DGS(3D Gaussian Splatting) 연구의 새로운 방향 중 하나는 움직이는 다이나믹 씬을 D-NeRF(Dynamic NeRF)와 4DGS(4D Gaussian Splatting)로 복원하는 것이다. 본 연구는 이를 위한 촬영 환경 세팅을 구성하기 위해 3ds Max 기반 가상환경에 다수의 카메라를 배치하고, 가상 모델로 렌더링한 인조 데이터 세트를 생성하여 복원 실험을 수행하고 품질을 정성·정량적으로 비교하였다. 실험 결과, 카메라 간격을 좁힌 직선형 배치에서 복원 품질이 우수했으며, 카메라 높이는 큰 영향을 미치지 않았다. 또한 빈 배경보다는 벽면에 마커를 부착하거나, 다양한 깊이를 지닌 소품을 사용해 모델을 가리지 않게 배치한 경우가 높은 품질을 보였다. 이러한 결과를 바탕으로 실제 환경에 카메라 리그를 제작하고 촬영한 영상을 통해 D-NeRF와 4DGS 복원이 가능함을 확인하였다. 향후에는 실제 환경 기반의 카메라 리그 제작 및 개선에 대한 후속 연구가 필요하다.
Abstract
An emerging direction in Neural Radiance Fields (NeRF) and 3D Gaussian Splatting (3DGS) research focuses on reconstructing dynamic scenes using approaches such as Dynamic NeRF (D-NeRF) and 4D Gaussian Splatting (4DGS). This study investigates optimal camera rig configurations for such reconstructions by first generating synthetic datasets in a virtual environment created with 3ds Max. Multiple virtual cameras were positioned to capture a moving 3D model, and the rendered sequences were used to evaluate reconstruction quality both qualitatively and quantitatively. The experiments demonstrated that a linear arrangement with closely spaced cameras yielded higher-quality results. Camera height had minimal impact, whereas backgrounds with depth—such as walls with tracking markers or props placed behind the subject—significantly enhanced reconstruction, provided they did not occlude the model. Based on these insights, a physical camera rig was constructed and tested in a real environment, confirming the validity of the virtual simulation results. Future research should refine real-world camera rig designs for D-NeRF and 4DGS, moving beyond synthetic setups to address practical constraints and optimization strategies.
Keywords:
NeRF, D-NeRF, 3DGS, Synthetic Data, 4DGS키워드:
인조데이터Ⅰ. 서 론
인공지능의 한 분야인 머신러닝 기술은 방대한 데이터를 목적에 맞게 자율학습하고 개선하는 기술로 영상 관련 기술산업을 포함한 거의 모든 산업 및 비즈니스 활동에서 전방위적으로 사용되고 있다. 3D 비젼 분야도 마찬가지로, 2020년 인공신경망을 사용하여 2D 이미지들을 학습해 3D 좌표와 색 정보 등을 추출하고 이를 바탕으로 영상으로 3D 모델의 이미지를 직접 생성하는 NeRF(Neural Radiance Fields) 기술이 처음 등장하였고[1], 2023년에는 3DGS(3D Gaussian Splatting) 기술을 통해[2] 실시간에 가까운 렌더 속도와 고품질의 이미지의 렌더가 가능해졌다. 2022년 타임지는 NVIDIA의 Instant NeRF를 2022년 최고의 발명 중 하나로 선정하기도 하였다[3]. 이러한 흐름에 따라 관련 연구들이 많은 기술적 진보를 이루고 다양한 분야에서 이를 활용하고자 하는 시도가 지속되고 있다.
최근 들어 이러한 NeRF와 3DGS를 프레임 별로 학습하여 시간에 따른 움직임 변화를 구현하려는 D-NeRF(Dynamic NeRF)와 4DGS(4D Gaussian Splatting) 기술 연구들이 등장하고 있는데, 기존의 3D 그래픽 제작 방식에서 3D 모델과 본 리깅, 애니메이션 작업 등 여러 단계의 파이프라인을 거쳐야 했던 작업들이 실제 객체와 공간의 움직임을 바로 3D 데이터화된 영상으로 구현할 수 있다면 영화, 게임, 메타버스, VFX(Visual Effects) 등 영상 관련 분야에서 가상데이터와 실제데이터를 쉽게 아우를 수 있는 획기적인 진화를 가져올 것이다.
본 연구는 아직 초기 단계인 D-NeRF 기술 개발 및 콘텐츠 분야 활용성을 연구하기 위해 D-NeRF 촬영 시에 고려해야 할 카메라 및 촬영 환경 세팅을 탐색하고자 하는 목적으로, 3D 그래픽프로그램 환경에서 가상공간과 모델로 렌더한 인조데이터들을 테스트하여 D-NeRF 촬영시스템에서 고려해야할 촬영 환경 조건들을 테스트하였다. 이미지 품질의 정성적, 정량적 비교분석을 통해 추출된 결과를 바탕으로 실제 촬영 환경을 세팅하고 멀티 카메라 리그를 통해 촬영한 뒤 실제 촬영데이터의 결과를 확인하였다.
Ⅱ. 움직이는 장면의 3차원 복원 및 다시점 촬영 장비에 관한 선행연구 탐색
2-1 NeRF와 3DGS
NeRF(Neural Radiance Fields)는 Mildenhall이 2020년 2차원 이미지에서 장면의 3차원 표현을 재구성하기 위한 딥 러닝 기반 방법으로 발표한 연구에서 처음 등장한 개념으로[1], 심층 신경망(DNN: Deep Neural Network)을 사용한다. 이때, SfM(Structure from Motion) 기법으로 사전에 계산된 각 2D 이미지의 카메라 위치 및 방향을 입력값으로 활용하여, 특정 3D 공간 좌표와 시선 방향에 따른 색상(RGB color)과 볼륨 밀도(σ)를 예측하도록 학습한다. 이렇게 추출된 데이터를 바탕으로 기존의 이미지에 없던 새로운 카메라 시점의 위치에 따른 대상의 RGB 색상 및 Alpha(투명도) 값을 볼륨 렌더링 기술로 이미지로 생성할 수 있다.
3DGS(3D Gaussian Splatting)는 2023년 Kerbl et al. 이 발표한 개념으로 3D 볼륨 데이터를 메시(Mesh)로 변환하지 않고 3D 가우시안으로 직접 렌더링하는 스플래팅(Splatting) 기반 렌더링 기술[2]이다. 이는 NeRF의 레이 마칭(ray-marching) 방식과 차별화된다. 3DGS는 NeRF와 마찬가지로 이미지와 영상에서 3차원 구조를 특정하는 SfM 기술을 사용하지만, 3D 포인트 위치에 색, 투명도, 크기 정보를 포함한 타원형의 가우시안들로 채워 이미지를 표현한다. 밀도가 낮은 데이터로도 전체적인 볼륨을 채워 빈 공간까지 불필요한 연산을 방지하기 때문에 HD(High Definition) 해상도에서도 실시간 렌더가 가능해지면서 최근 이러한 이미지 기반 3D 비젼을 구현할 때 대표적으로 쓰이고 있다.
NeRF와 3DGS 기술 모두 특별한 장비 없이 일반 카메라에서 촬영한 사진과 영상들만으로 3D 비젼을 구현할 수 있다는 점이 가장 큰 특징이며, SfM을 통해 추출한 데이터는 3D 메시로 직접 생성하는 것이 아니라 사용자 시점에 따라 화면에 이미지로 바로 출력하여 영상화한다.[4]
2-2 다이나믹 씬과 D-NeRF, 4DGS
기존의 NeRF 기술들이 정적인 객체와 공간을 다양한 시점에서 확인하고 렌더할 수 있었다면, 2021년 고정되지 않은(Non-Riggid)한 객체를 구현하기 위한 NR-NeRF 연구[5]와 K. Park et al. [6] 연구를 시작으로 2023년부터 동적인 움직임을 구현하기 위한 연구들도 진행되기 시작하였다.
A. Pumarola et al.[7]은 2021년 D-NeRF 방식을 제안하였는데, 이는 주로 단일 카메라(monocular)로 촬영한 영상을 이용해 동적 장면을 재구성하는 연구였다. 기존 NeRF에 시간 변수를 추가하여 프레임별 변화를 학습하고 새로운 시점의 이미지를 렌더링할 수 있다. 본격적인 다이나믹씬을 고화질로 정확히 구현하기 위해서는 본 연구에서처럼 여러 카메라를 사용한 다시점 영상을 사용하는 연구들이 주를 이루고 있다.

Visualization of composition with 4D Gaussians at G Wu et al[9]
J. Luiten et al.[8]은 2023년 동적 장면을 모델링하기 위해 27대의 학습용 카메라와 4대의 테스트용 카메라를 사용하여 첫 프레임의 3DGS를 학습한 뒤 시간에 따른 3D 가우시안의 이동과 회전을 추적하여 실시간으로 3D로 움직임을 재구성하는 Dynamic 3D Gaussian 연구를 발표하였다.
G Wu et al.은 2023년 시간(time) 변수를 추가하여 학습하는 방식을 3DGS에도 적용한 논문을 발표하며 3DGS에 동적인 개념을 더한 4DGS 표현을 제안하였다[9].
앞에서 살펴본 것처럼 기술 논문들에서는 이러한 움직이는 객체 혹은 움직임이 포함된 장면을 다이나믹 씬(Dynamic Scene)이라는 용어로 사용하고 있으며, 아직까지는 다이나믹 씬을 다룬 기술 자체에 대해서는 기술의 종류에 따라 다양한 명칭이 혼용되고 있다. 본 논문에서는 기술 자체를 볼륨렌더링 방식으로 나눠 D-NeRF와 4DGS라 칭하기로 정한다.
기존의 정적인 장면을 촬영할 경우에는 하나의 카메라를 사용해 다양한 시점을 이동하면서 촬영한 영상과 사진을 사용해 재구성이 가능하였으며, 앞선 연구처럼 싱글 뷰 만으로도 학습을 강화하거나 생성형 인공지능 등을 활용해 3D로 재구성하는 연구들[10]도 진행되고 있지만 본격적인 다이나믹씬을 고화질로 정확히 구현하기 위해서는 여러 카메라를 사용한 다시점 영상을 사용한 연구들이 주를 이루고 있다.
2-3 볼류메트릭 비디오와 다시점 카메라 리그
앞서 살펴본 NeRF와 3DGS 분야가 아니더라도, 시청자들이 3차원의 시점을 직접 조절하여 이동하여도 재생할 수 있도록 하는 영상에 대한 개념은 그동안 다양한 분야에서 연구되어 왔다. 이러한 개념의 영상은 자유시점 비디오(FVV: Free-viewpoint Video)란 용어로 흔히 6개축(Dof: Degrees of Freedom)를 사용하여 어느 각도에든 재생 가능하도록 3D 공간 상에 재구성한 영상을 의미한다. 영화 매트릭스의 특수효과나 스포츠 중계의 정지화면과 같은 장면에서도 찾아볼 수 있으며, 최근에는 볼류매트릭 비디오(Volumetric Video)란 이름으로도 사용되고 있다. 특히 VR(Virtual Reality)와 같은 가상공간에 실제 피사체의 움직임을 그대로 재현해오기 위한 목적으로 활발히 연구되고 있다.
이렇게 다양한 각도의 영상을 재구성하기 위해서는 피사체를 둘러싸고 다양한 각도에서 동시에 영상이 촬영되어야 하기 때문에 객체를 둘러싸도록 다양한 형태의 카메라 리그를 제작하여 수십 개의 비디오카메라를 설치한 뒤 동시에 영상을 촬영하도록 하는 다시점 카메라 리그가 필수적으로 제작되어야 한다.
T. Kanade et al.의 1997년 연구[11]에서는 가상화 스튜디오(Virtualizing Studio) 란 이름으로 직경 5미터의 정다면체 지오데식 돔(geodesic dome)구조 리그에 51개의 NTSC 비디오 카메라와 90도 수평 시야각을 가진 렌즈를 그림2처럼 설치하였고, 공통의 전기적 동기신호를 사용해 다양한 각도의 흑백 영상을 동시에 촬영하는 방식을 사용하였다.

The Virtualized Reality studio of T. Kanade & P. Rander [11], (a) conceptual; (b) 3D Dome
J. Carranza et al.[12]은 2003년 7개의 IEEE 1394 (FireWire) 방식 디지털 캠코더를 실내의 기둥형 봉에 대상을 둘러싸고 바라보는 수렴형 구조로 세팅하여 영상을 촬영하였다.
디지털 기반 촬영과 편집 소프트웨어 기술이 발전하면서 이러한 다시점 카메라 리그들의 처리 방식도 한층 더 용이해졌다.
2010년대 중반부터는 MR(Mixed Reality)과 VR에 관심이 높아지면서 이러한 자유시점 비디오에 대한 연구가 본격적으로 진행되었는데, 인텔은 2018년 LA의 25,000 평방 피트의 스튜디오를 기반으로 약 926m2의 돔 공간에서 배우나 객체를 볼류메트릭 3D로 캡쳐할 수 있도록 설계한 전용 스튜디오 공간의 개설을 공식 발표하였다. 수천 개의 깊이 센서와 카메라를 사용해 광대한 데이터를 촬영하고 광섬유를 통해 이동한 후 분당 6테라바이트의 속도로 인텔서버 전체를 사용해 알고리즘 처리하도록 하였다[13].
마이크로소프트 역시 2010년부터 관련 기술을 연구해오다 2018년 샌프란시스코에 볼류메트릭 비디오를 촬영하기 위한 혼합현실 캡쳐 스튜디오(Mixed Reality Caputre Studio)를 구성하였다. 25x25 피트의 공간을 106대의 카메라 장비와 그린스크린 배경, 조명이 둘러싸도록 배치했으며 수십대의 서버가 카메라에서 촬영한 비디오를 초당 10GB로 처리하여 고품질의 다시점 영상을 구현할 수 있도록 하였다[14]. 마이크로소프트의 경우 인텔의 스튜디오보다 상대적으로 작은 규모이지만, 분해하여 다른 공간에서도 촬영할 수 있도록 리그를 구성했으며 이동할 경우 58개의 카메라 만으로도 촬영할 수 있도록 하였다.
M. Işık et al.[15]은 2023년 160대 카메라에서 1200만 화소로 인간의 전신 움직임을 촬영한 데이터를 기반으로 NeRF를 사용해 고해상도의 다이나믹 씬을 재구성하였다.
다시점 카메라 리그와 촬영 시스템을 구성하기 위해서는 다양한 시점을 포착하기 위한 다수의 카메라를 여러 각도로 리그 위에 배치하여 촬영 환경을 구성하고, 센서나 외부 컨트롤러를 사용해 촬영 신호를 송신하고, 촬영된 정보를 실시간 혹은 녹화가 끝난 후에 오프라인으로 가져와 영상들을 추출한다. 배경을 인물에게서 쉽게 제거하기 위해 그린스크린과 같은 단순한 배경을 사용하며 여러 카메라에서 일관된 카메라 보정값을 얻을 수 있도록 전처리를 거친다. 추출한 영상은 알고리즘을 사용해 이미지들을 각도별로 정합하고 포토그래메트리나 NeRF와 같은 컴퓨터 비전 기술을 사용해 3D 볼륨으로 재구현하고 시청자가 볼 수 있도록 영상으로 렌더링하는 단계를 거치게 된다.
일반적으로 가상시점의 품질은 설치된 카메라 수가 많아질수록 높아지게 되며, 그만큼 처리해야 하는 이미지의 데이터가 급등하게 된다. 카메라의 배치방식과 카메라의 밀도(갯수)는 가상시점의 탐색 범위와 이미지 품질에 영향을 미치기 때문에 전체적인 장비의 비용과 이미지의 품질에서 절충을 취할 수 밖에 없다. 돔 형태의 리그 시스템은 조명과 환경을 제어할 수 있는 실내 스튜디오 제작 환경에서 주로 사용되며, 야외 환경에서도 일렬로 피사체를 둘러싸는 원형 배열 리그를 사용해 다각도 시점의 영상을 촬영한다[16].
볼류메트릭비디오 관련 기술은 방대한 고품질의 촬영 데이터를 기반으로 초고화질의 메시를 사용한 3D 볼륨 데이터로 재구현해야 하므로 몇 일에서 몇 주 가량의 긴 렌더링 시간이 소요된다[17]. 반면 이제 연구가 시작되는 D-NeRF와 4DGS 기술을 사용하면 상대적으로 적은 카메라만을 사용하여 빠른 시간 내에 3D 렌더된 다시점 영상을 제작할 수 있다. 특히 앞으로 연구들이 거듭될수록 데이터처리 속도의 단축과 품질개선이 이루어질 것이라 기대된다. 이러한 D-NeRF와 4DGS 기술을 적용하기 위한 다시점 카메라 리그를 구성하기 위해서는 포토그래메트리 기술과 다른 최적화된 촬영 환경 세팅 요건을 찾기 위한 실험이 선제 되어야 할 것이다.
Ⅲ. 촬영환경 세팅 비교를 위한 인조데이터 기반 실험 및 연구 설계
3-1 카메라와 촬영 환경 설정 및 실험 방법
본 논문은 D-NeRF와 4DGS 기술을 적용하기 위한 다시점의 멀티카메라들로 움직이는 피사체를 촬영하는 목적으로 어떠한 요소를 고려하여 카메라 시스템 및 촬영 환경을 구성해야 하는지를 실험해보는 것이 목적이다.
D-NeRF와 4DGS를 만들기 위해서는 우선 동일 시간에 피사체를 여러 각도에서 찍은 이미지들을 확보하여 NeRF 혹은 3DGS를 구성할 수 있어야 한다. 여러 각도에서 찍은 사진을 바탕으로 3D 좌표 값을 추출하는 원리이므로, 이미지에 찍힌 피사체가 최대한 겹쳐야 정확한 위치를 추출할 수 있기 때문에 가능한 많은 부분을 서로 겹쳐서 비교할 수 있도록 카메라의 렌즈는 여러 카메라의 시야가 충분히 중첩되도록 넓은 화각(Wide FoV)을 확보하는 것이 유리하다. 다만, 이미지 가장자리의 심한 왜곡은 SfM 과정에서 오류를 유발할 수 있으므로, 렌즈 왜곡이 소프트웨어적으로 보정 가능한 수준의 렌즈를 선택하는 것이 중요하다. 선행연구에서 본 것처럼 현재의 많은 포토그래메트리 전문 촬영 장비들은 DSLR과 같은 고가의 카메라를 수십대에서 수백대를 사용하기 때문에 전체 시스템을 구성하기 위해서는 매우 고비용이 필요하며. 그리고 카메라를 고정하기 위해서 카메라의 수와 각도에 맞춰 맞춤형으로 리그를 제작해야 할 수밖에 없다.
따라서 제작 전에 데이터가 최적으로 구현될 수 있도록 사전에 실험을 통해 촬영에 참고할 수 있는 촬영 조건을 추출한다면 전체적인 촬영 시스템의 설계와 제작에 효율성을 높일 수 있다.
본 논문에서는 이러한 카메라의 배치와 촬영 환경 등의 요건만으로 실제로 D-NeRF와 4DGS 데이터 구현에 영향을 미치는지를 실험해보려 한다. 소프트웨어의 기술 개선이 주가 아니라, 물리적 환경과 촬영 요건 차이에 따른 결과를 비교하는 것을 범위로 제한한다.
현 논문에서 시스템을 제작하기 위해 80도 화각을 갖춘 웹캠 24~40대를 사용하는 것을 기준으로 설정하였으며, 적은 카메라의 수로 피사체를 찍은 이미지들이 최대한 중첩될 수 있도록 화각이 넓으면서 비용이 적은 HD 해상도의 웹캠 카메라를 선택하였다.
D-NeRF와 4DGS를 구현하기 위해서 4DGS와 3DGStream 2가지의 코드 베이스를 활용하여 4D 구현을 진행하였으며, 데이터가 제대로 복원되는지를 확인하기 위해 먼저 첫 프레임을 3DGS로 복원한 후에 제대로 복원되는 데이터를 4D로 복원하는 순서로 실험을 진행하였다.
4DGS로 복원된 결과는 프레임별로 PLY 파일들이 생성되며, 그림 3과 같이 슈퍼수플랫(SuperSuplat) 뷰어에 전체 프레임별 PLY(Polygon File Format/ the Stanford Triangle Format) 파일들을 한번에 드래그해 가져와 프레임 별 재생 및 데이터 확인, 실시간 뷰를 이미지와 영상으로 렌더가 가능하다.

SuperSuplat screenshot of PLY frame datas*Screenshot of Korean ver. 'SuperSuplat’
프레임 별로 생성된 GS(Gaussian) 파일의 결과는 스플릿의 수 및 생성 형태를 정성으로 비교하며, 품질 차이가 확연하지 않은 결과물들은 추가적으로 정량 평가 지표를 사용하여 결과를 비교하였다.
3-2 인조데이터의 기본 세팅
촬영 시스템을 제작하기 위한 테스트를 위해서 가장 좋은 방법은 실제로 여러 대의 카메라들을 원하는 위치에 맞추어 고정시켜 실제 인물과 소품 등을 사용해 촬영한 실제 데이터 결과물을 비교하는 것이 제일 최선일 것이다. 하지만 실제로 수십 대의 카메라를 먼저 구매하거나 대여하고 물리적인 촬영 환경을 준비하여 원하는 위치대로 배치할 수 있는 리그를 제작하는 것만으로도 많은 비용이 들며, 이를 촬영 결과에 따라 다시 수정하는 작업도 비용과 시간, 물리적 제한이 따를 수 있다.
따라서 이번 논문에서는 실제 촬영을 준비하기 위해서 3D 가상환경에서 가상의 카메라와 모델, 환경을 세팅하여 이미지와 영상을 렌더한 후 이를 사용해 4DGS를 재구성한 결과물을 비교한다. 3ds 맥스(3ds MAX) 프로그램의 피지컬 카메라(Physical camera)를 사용하여 현실세계와 호환할 수 있는 시스템 유닛 안에서 표 1처럼 실제 소니 cmos 센서의 웹캠 카메라와 유사한 화각과 카메라 설정을 적용할 수 있도록 하여 실제 데이터와 차이를 최대한 줄이도록 하였다.

Physical camera setting of 3ds MAX
다이나믹 씬의 피사체로 재구현이 용이하도록 작업모자와 작업복을 입은 180cm의 남성 모델을 선택하였고, 모션캡쳐 데이터를 사용해 짧은 액션을 구현하였다. 실험 영상은 24fps 기준 3초로 전체 72프레임의 짧은 영상을 제작한다.
3-3 제어 변수 설정
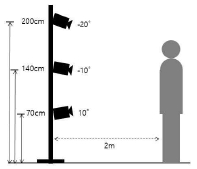
일반적인 NeRF와 3DGS 제작에서는 주요 피사체를 중심으로 상단, 중앙, 하단 3단계의 높이에서 각각 촬영을 한 데이터를 사용할 것을 권장한다. D-NeRF와 4DGS에서도 마찬가지로 피사체를 동시에 촬영하기 위해서 표2처럼 한 위치에서 상단과 정면, 하단 3가지 높이로 카메라를 3단 배치하여 촬영하는 것을 기본 카메라 라인 배치로 설정하되, 전체적인 카메라 라인의 배치 위치와 간격, 인물에 따른 높이 조절을 변수로 다르게 세팅한 후 그 결과를 실험으로 비교한다. 또한 인물만이 아니라 소품들이 배치된 스튜디오나 로케이션과 같은 실제 환경을 포함하여 제작할 경우를 고려하여 배경 설정에서의 변수도 실험하려 한다.
Comparison of camera rig structure
본 논문에서는 카메라 리그의 배치 형태, 피사체의 키나 자세에 따른 카메라 높이 차이, 배경 설정의 차이 3가지 요건을 비교하였다.
NeRF와 3DGS 제작을 목적으로 촬영할 경우 카메라의 위치 이동 혹은 회전을 통해 다양한 각도의 피사체 정보를 획득하는 것이 중요하다. 따라서 피사체 전체가 잘 보이도록 360도로 둘러싸고 회전하며 촬영하거나, 전면부만을 위주로 둘러싸고 180도 가까이 회전하며 촬영하는 아크 샷, 또는 직선으로 카메라를 이동하는 패닝 샷으로 연속사진 혹은 영상을 촬영하게 된다. D-NeRF와 4DGS는 마찬가지로 다양한 각도의 피사체 정보를 동시에 획득해야 하므로, 이러한 카메라 동선 대신 여러 대의 카메라를 동시에 배치하여 촬영해야 할 것이다.
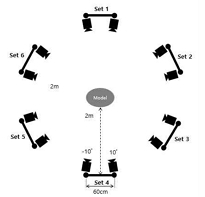
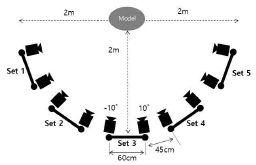
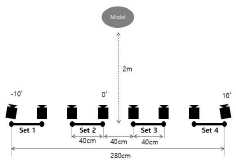
따라서 카메라의 리그 배치 구조를 결정하기 위하여 첫 번째 실험을 진행하였다. 3가지의 경우를 비교하였는데, 표2처럼 선행연구들을 참고하여 360° 전 방향을 촬영할 수 있도록 6각 구조로 피사체를 둘러싼 경우(360° 육면형)와 피사체 전면부를 둘러싸고 180° 아크형으로 배치하는 경우, 정면을 기준으로 일직선으로 배치하는 경우를 비교하였다.
세 가지 경우 피사체를 수직 시점에서도 다양한 각도로 촬영할 수 있도록 모두 상단, 중앙, 하단의 3단 배치를 2줄씩 배치한 리그 세트를 기준으로 360° 육면 배치는 6개의 세트 총 36개의 카메라를, 180° 아크형 배치는 5개의 세트, 총 30개의 카메라를 배치하였으며, 직선형은 4개의 세트, 총 24개의 카메라를 배치하였다.
360° 육면형과 180° 아크형은 리그 내부 카메라 라인의 간격을 60cm로 설정하였고, 360° 육면형은 다른 카메라세트 간의 간격은 6~70cm로 먼 거리를 둔 반면, 180° 아크형은 45cm 간격, 직선형은 카메라 라인의 간격도 40cm로 줄이고 다른 카메라 세트와의 간격도 40cm로 두어 더욱 촘촘하게 배치하였다.
180° 아크형 배치는 정면을 기준으로 양쪽의 카메라 열을 10°씩 꺾어서 피사체 중심으로 바라보도록 카메라의 각도를 조절하였으며, 직선형 배치는 가장 좌측과 우측 열의 카메라를 제외하고는 정면 0°로 각도를 조절하고, 가장 좌측과 우측 카메라는 각각 안쪽으로 10°씩 각도를 조절하였다.
이러한 카메라 배치에 따른 데이터 세트는 표 3에서 1-1, 2-1, 2-3에 해당한다.
Data set list
피사체가 카메라의 앵글안에 잘리지 않고 들어오기 위해서 피사체와 카메라와의 거리는 2m로 설정하였다.
이를 비교하기 위한 피사체 모델의 자세는 선 채로 손을 흔드는 자세(1-1), 책상 위에 앉아있는(2-1, 2-2) 두 가지의 자세를 사용하였다.
실제 촬영에서 인물의 키나 동선, 자세와 촬영 환경에 따라 피사체의 기본 높이는 달라질 수 있다. 따라서 두 번째 실험은 이러한 피사체의 높이에 따라 카메라의 높이를 조절하는 변수를 살펴보려 한다.
두 번째 실험은 2가지의 모션 캡쳐 데이터를 사용하였는데, 첫 번째 동작은 의자에 앉아서 대화를 하는 동작이고, 다른 동작은 서서 발걸음을 앞으로 옮기며 대화를 하는 동작이다.
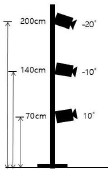
먼저 피사체 모델의 선 키(180cm)에 맞추어 표 4처럼 카메라의 3단 기본 높이는 상단(200cm)과 정면(140cm), 하단(70cm) 높이로 설정하였다.
Comparison of camera height by posture
앉아있는 자세는 의자와 함께 테이블을 추가하여 하반신을 가리고 상반신에 집중하여 촬영 및 재구성하도록 하였다.
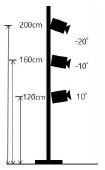
앉은 자세의 경우는 카메라 화면 안에 피사체가 들어오도록 카메라 앵글을 확인하며 피사체의 자세에 맞추어서 상단(180cm), 정면(135cm), 하단(50cm) 높이의 3단으로 카메라의 높이를 조절하였다.
이를 비교하기 위해 표 3의 2-2, 3-2(앉은 자세)와 3-1, 3-3(선 자세)와 같이 데이터 세트를 제작하였다.
NeRF와 3DGS 기술 모두 디테일한 피사체를 다룰수록 재구현이 잘되는 특성을 갖고 있기 때문에 세 번째 실험에서는 표 5와 같이 3가지의 배경조건을 설정하여 비교하였다. 먼저 아무 배경과 소품이 없이 인간 모델만 촬영한 경우와 뒷 배경에 여러 가지 가구와 소품을 배치한 경우, 마지막으로 흑백마커들을 뒷 배경에 일정한 간격으로 부착한 경우이다. 이 변수의 비교를 통해 향후 D-NeRF 및 4DGS 촬영 시에 적절한 환경요건을 어떻게 구성해야 할지 참고할 수 있다.
Comparison of background scene
소품을 배치한 경우는 가장 먼 거리의 소품과 피사체 간에 2m 거리를 두고 그 사이에 여러 가지 다양한 가구와 소품들을 배치하였다. 마커의 경우에는 증강현실 등에 많이 쓰이는 흑백 패턴인 아루코 마커(Aruco Marker)를 사용하여 가로세로 20cm 크기로 좌우 60cm 상하 20cm 간격을 두고 가로 5줄, 세로 6줄 총 30개의 마커를 사용해 마커 벽을 구성하였으며, 이 마커 벽은 피사체와 1.5m 거리를 두고 배치하였다.
이를 비교하기 위해 표 3의 3-1(소품 배경)과 3-2,3-3(마커 배경), 3-4(빈 배경)과 같이 데이터 셋을 제작하였다.
Ⅳ. 실험 결과
4-1 데이터 생성 결과
먼저 1차 실험에서 360° 육면 구조로 36개의 카메라를 배치한 리그의 데이터 세트 1-1의 첫프레임을 3DGS로 복원(Reconstruction)한 결과, 표 6에서 보듯이 인물의 제대로 된 형상이 생성되지 않고 뭉개지는 결과가 나오게 되었다. 결과를 개선하기 위해 표 6의 1-1처럼 배경에 카메라 리그 모델이 추가되어 있는 영상에서 1-2처럼 배경을 지워 인물만 남도록 한 후에 복원한 결과는 이전보다 조금 더 개선되었다. 하지만 4D로 복원한 결과를 살펴보았을 때, 4DGS 코드 베이스에서는 복원된 결과물에서 움직임이 없이 멈춘 형태로 복원되었으며, 3DGStream 코드 베이스에서는 움직임 자체는 만들어졌지만 객체의 일부분들이 빈 상태로 복원되었다. 또한 1-2처럼 배경을 지운 경우에는 제대로 된 객체의 형태가 보이지 않고 블러 처리한 듯이 불분명하게 생성되었다.
Reconstruction result of data set 1-1, 1-2
명확한 데이터를 얻기 위해 실험 데이터 셋 2-1은 피사체의 정면을 중심으로 180° 아크형으로 둘러싸도록 배치를 하였고, 2-2는 일직선으로 배치하였다. 여기에 더불어 피사체의 자세도 앉은 자세로 책상으로 하반신을 가리게 하고 카메라의 높이를 조절해 피사체의 상반신 전면을 중점적으로 구현할 수 있도록 구성하였다. 또한 카메라의 높이를 앉은 자세에 맞춰 120/160/200cm 높이로 조정하였다.
실험 결과, 표 7에서 보듯이 4DGS와 3DGStream 모두 이전보다 훨씬 개선된 형태로 복원이 가능하였으며, 특히 3DGStream에서는 첫 프레임 복원에서 매우 디테일한 복원이 가능하였다.
Reconstruction result of data set 2-1, 2-2
3DGStream의 결과를 비교하였을 때, 180° 아크형 구조로 배치한 2-1 데이터 세트에서 복원된 스플릿(Splat)은 302,924개로 직선형 구조로 배치한 데이터 세트 2-2의 스플릿 개수인 137,669개에 비해 2배가 넘는 개수로 복원되어 이미지 품질이 더욱 정밀하고 높은 밀도로 표현되었다. 표 7의 모델의 정면과 측면 디테일 샷을 비교해보면 직선형 구조에서는 데이터 세트에서 보이지 않는 뒤통수와 상체 뒷면은 비어있거나 매우 성긴 밀도로 복원되어 있는 것을 확인할 수 있다.
반면에 움직임의 구현을 비교해보자면, 2-1의 70개의 프레임별 데이터는 스플릿들의 변화를 복원하지 못하여 첫프레임에서 멈춘 상태로 움직임이 만들어지지 않고 배경의 일부만 흔들리는 것처럼 구현되었다. 반면 2-2는 프레임 별로 스플릿의 이동과 변화가 생성되어 표8에서 보듯이 프레임별 움직임이 생성되었다. 2-1 데이터 세트에서 움직임이 생성되지 않은 이유는, 초기 프레임에서 매우 촘촘하고 많은 수의 가우시안이 생성되어 프레임 간의 움직임 벡터(motion vector)를 추적하는 최적화(optimization) 과정이 안정적으로 수렴하지 못했기 때문으로 추정된다. 즉, 정적 장면 표현은 우수했으나 동적 변화를 학습하는 데에는 어려움을 겪은 것으로 보인다.
Reconstruction result of data set 2-2, 3-1, 3-2, 3-3
직선형 배치만이 움직이는 다이나믹 씬 구현에 성공하였기 때문에 이후 실험은 직선형 배치로 고정하였다. 또한, 여러 데이터 세트에서 4DGS 코드 베이스보다 3DGStream 코드 베이스가 더 안정적으로 동적 결과물을 생성하였으므로, 이후 변수 비교 실험은 3DGStream 코드 구조를 기반으로만 복원하여 비교하기로 한다.
1차 실험의 결과를 볼 때 360° 육면형과 180° 아크형, 직선형의 순서대로 카메라가 담는 시점의 범위 폭과 카메라의 개수는 줄어드는 대신 카메라 간의 간격이 점차 좁혀진 구조를 가지고 있는데, 이는 카메라의 총 개수보다 카메라 간의 간격을 촘촘히 둘수록 개선된 결과를 얻을 수 있다고 볼 수 있다.
앞선 실험 결과에서 가장 좋은 결과를 얻은 2-2 데이터 세트는 동적 움직임에 따른 결과물 복원을 성공시키기 위해서 카메라의 배치구조 외에 앉은 자세에 맞춰 카메라 높이를 조절하여 자세와 높이라는 변수가 추가되었다. 이 변수에 따른 결과만을 비교하기 위해, 2-2와 동일하게 직선형 구조로 카메라를 배치하되, 이번에는 서서 팔과 자세와 그에 맞춰 처음 설정한 대로 카메라 높이를 맞춘 3-1 데이터 셋을 3DGStream 코드 기반의 방식으로 복원하였고 그 결과를 2-2와 비교하였다.
3-1 데이터 세트를 복원한 결과는 표8에서 보듯이, 스플릿은 156,183개가 생성되어 2-2보다 많은 갯수의 스플릿이 생성되었는데, 같은 배경임에도 2-2의 앉은 자세에서 가려져서 구현되지 않았던 책상 아래와 모델의 하체 부분까지 복원됨에 따른 것으로 보인다.
2-2와 3-1 데이터 세트 복원 결과물의 정량적 품질 차이를 비교하기 위해 PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index Measure), LPIPS (Learned Perceptual Image Patch Similarity) 3가지 지표를 사용한 분석을 실행하였다. PSNR은 원본 영상 대비 재구성 영상의 신호 손실 정도를 나타내는 척도로, 값이 높을수록 왜곡이 적고 품질이 우수함을 의미한다. 일반적으로 30 dB 이상이면 고화질로 간주된다. SSIM은 영상의 구조, 명암, 질감 등의 유사성을 평가하는 지표로, 1에 가까울수록 원본과 구조적으로 유사한 영상임을 나타낸다. 이는 인간의 시각적 인지 특성을 반영하여 단순한 픽셀 간 차이보다 더 신뢰할 수 있는 품질 비교를 제공한다. LPIPS는 딥러닝 기반의 인지 유사도 지표로, 두 영상 간의 시각적 차이를 신경망의 특성 공간에서 계산한다. 값이 낮을수록 인간이 보기에 더 유사한 이미지로 판단되며, 기존의 전통적 지표들이 포착하기 어려운 시지각적 차이를 정량화할 수 있다. 이 세 지표는 서로 보완적인 성격을 가지며, 단일 수치보다는 상호 비교를 통해 보다 신뢰도 높은 품질 평가가 가능하다.
데이터 세트에 포함되지 않은 새로운 위치의 카메라 위치에서 3ds 맥스(3ds max)로 렌더한 이미지를 원본(Gtround Truth)로 설정하고, 3ds 맥스에 가우시안스플릿 PLY 파일을 V-ray 렌더러를 통해 가져와 원 메시모델과 동일한 위치와 크기로 배치한 뒤 앞서와 동일한 카메라 위치에서 렌더한 이미지를 비교대상으로 설정하였다. 이렇게 설정한 1개의 카메라 위치에서 1, 15, 30, 45,60프레임 별로 렌더한 5개의 이미지들을 대상으로 비교 분석하였다. 두 이미지세트들의 실제 품질 분석 수치는 표 9와 같다.
Image quality metric result of 2-2, 3-2 data
2-2 데이터 세트의 평균 PSNR은 약 21.24로, 3-1의 평균 PSNR 28.71에 비해 약 7.47 dB(decibel) 낮은 수치를 기록하였다. 이는 2-2의 렌더링 이미지가 원본 대비 신호 손실이 더 많고, 전반적인 해상도 품질이 떨어짐을 의미한다. 구조적 유사성을 나타내는 SSIM 역시 2-2는 평균 0.801로, 3-1(0.939)보다 0.138 낮아 상대적으로 형태 보존이 불안정함을 확인할 수 있다. 특히 시각적 유사성을 반영하는 LPIPS 수치에서는 2-2가 평균 0.175로 3-1(0.077)보다 약 2.3배 높은 값을 보여, 시지각적으로 원본과 큰 차이를 보였음을 알 수 있다.
세부적으로 살펴보면, 2-2의 모든 프레임에서 LPIPS가 0.17에 가까운 수치로 고르게 높게 나타났으며, 이는 책상 등 소품에 의해 피사체 일부가 가려져 있기 때문에 렌더링 품질이 일정 수준 이하로 제한되었음을 시사한다. 특히 2-2의 PSNR은 최저 20.90에서 최고 21.51 사이에 머물러, 프레임 간 품질 편차는 크지 않지만, 전반적으로 낮은 수준을 유지하였다.
이러한 결과는 카메라 높이를 모델의 자세에 맞추는 것은 크게 영향을 주지 않고, 소품이 피사체의 신체 일부를 가리는 조건이 있을 경우, 신체 인식 및 3D 재구성이 어려워져 렌더링 품질 저하로 이어질 수 있음을 시사한다. 반면, 피사체가 완전히 드러나 있는 3-1의 경우 높은 PSNR과 SSIM, 낮은 LPIPS 값을 기록하며 전반적으로 안정적인 품질을 유지한 것으로 분석된다.
따라서, 자세 및 장면 구성 요소에 따라 3D 영상 품질에 미치는 영향이 상당하며, 특히 피사체 일부가 소품에 의해 차폐되는 경우 품질 저하가 현저하게 나타날 수 있음을 확인할 수 있다. 이는 뒷 배경 조건을 달리한 3-2, 3-3, 3-4의 품질 분석 결과와도 비교했을 때 책상으로 가린 2-2와 3-2가 현저히 낮은 수치를 보여주는 것과도 일치한다.
앞선 데이터 세트 2-2와 3-1에 더하여 배경과 소품의 세팅의 영향력을 추가로 비교하기 위해 동일한 모델 동작과 카메라 높이에서 표 8에서처럼 뒷 배경을 마커로 세팅한 3-2와 3-3 데이터 세트, 소품을 모두 제외한 3-4 데이터 세트로 복원결과를 비교하였다.
복원 결과, 소품 배경의 앉은 동작으로 제작된 2-2의 스플릿 수는 70,043개인 반면, 마커 배경의 동일한 앉은 동작으로 제작된 3-2의 스플릿 수는 221,949개로 생성되었다. 하지만 생성된 스플릿의 30% 가까이가 표 10에서 보듯이 불필요하게 전면부에 노이즈 화하여 생성되었다. 이는 앞서 살펴본 것과 같이 책상 소품으로 차폐되어 복원결과가 낮아진 때문으로 보인다.
Details comparison of 3-2, 3-3 in rings mode view
소품 배경의 선 자세로 제작된 3-1의 스플릿 수는 156,183개, 마커 배경의 선 자세로 제작된 3-3의 스플릿 수는 144,431개로 생성되었다. 배경 소품의 개수가 많고 다양한 뎁스를 표현할 수 있어 스플릿의 생성 갯수에서 유의미한 차이가 있을 것으로 추측했지만 실제 결과에서는 큰 차이를 보이지 않았다.
반면에 빈 단색 배경의 3-4 복원결과의 스플릿수는 83,662개로 적은 숫자로 생성되었으며, 첫 프레임에서는 복원 품질에 큰 차이는 없었지만 이후 프레임으로 갈수록 표 9에서 보듯이 배경의 스플릿들 위치가 흩어지며 품질 저하가 발생했다.
정량분석의 경우, 먼저 책상 앞에 앉아있는 동작과 책상 소품을 중심으로 뒤 마커를 소품으로 둔 경우인 3-2의 복원결과를 앞서 소품을 배경으로 뒀던 3-2 데이터 셋의 복원 결과와 정량적으로 비교하였으며 3-2의 분석 수치는 표 11과 같다.
Image quality metric result of 3-2 data
분석 결과, 3-2는 PSNR 17.75, SSIM 0.724, LPIPS 0.287로, 전반적으로 2-2에 비해 3-2가 더 낮은 화질을 나타내었다. 특히 PSNR 차이는 약 3.5 dB에 이르며, 이는 3-2에서 신호 왜곡이 더 많이 발생했음을 의미한다. 또한 LPIPS가 2-2보다 높다는 점은, 3-2의 이미지가 시각적으로도 원본과 더 유사하지 않으며 인지적 품질이 저하되었음을 보여준다.
구체적으로 3-2의 모든 프레임에서 PSNR은 18 dB 미만으로 매우 낮은 수준을 유지하였으며, SSIM 역시 0.73~0.74 사이에 머물러 영상의 구조적 일관성이 부족함을 시사한다. 이는 실제로 3-2의 이미지들에서 모델 앞과 주변 배경에 불필요한 스플릿이 다수 생성되어 노이즈처럼 보이는 현상과도 일치한다. 이는 마커 기반 배경이 재구성 과정에서 모델 및 주변 오브젝트, 배경과의 경계를 혼동하게 만들었을 가능성을 시사한다.
반면, 2-2 데이터 세트는 상대적으로 깨끗한 결과를 보였으나, 스플릿 수 자체가 낮아 전반적으로 흐릿하고 뭉개지는 현상이 나타났다.이는 신호 보존 측면에서는 3-2보다 우수하지만, 세부 묘사력이 떨어진다는 것을 의미한다.
이번에는 전신이 잘보이게 선 자세에서 소품을 배경으로 둔 3-1과 마커 배경을 둔 3-3, 단색의 빈 배경을 둔 3-4의 복원 결과 품질을 정량적으로 비교하였다. 3-3과 3-4 이미지세트들의 실제 분석 수치는 표 12와 같다.
Image quality metric result of 3-1, 3-3, 3-4 data
표 12에서 보듯이 3-3 이미지 세트는 평균 PSNR 27.48, SSIM 0.893, LPIPS 0.103를 보여 3-1의 수치가 전반적으로 더 우수한 품질을 보여준다. PSNR 수치가 높다는 것은 원본 대비 신호 손실이 적다는 것을 의미하며, SSIM이 높다는 것은 구조적 유사성이 뛰어남을 나타낸다. 특히 LPIPS는 인간의 시지각적 유사성을 반영하는 지표로, 3-1 세트의 낮은 수치는 시각적으로 원본과 더 유사한 품질을 지닌다는 것을 보여준다.
세부적으로 보면, 3-1 세트는 평균 PSNR 28.71, SSIM 0.939, LPIPS 0.077으로 높은 품질을 유지한 반면, 3-3 세트는 60프레임에서 LPIPS가 0.134로 높게 나타나 시지각적 품질 저하가 관찰되었다. 이러한 결과는 3-1 이미지 세트가 전체적으로 더 안정적이고 원본과의 일관성이 높은 복원 결과를 보여준다고 볼 수 있다.
따라서, 본 실험에서는 3-1 세트가 3-3 세트에 비해 객관적 신호 품질, 구조 보존, 그리고 시각적 유사성 측면에서 모두 우수한 성능을 보였으며, 프레임 간 편차 또한 상대적으로 적어 더 높은 품질의 일관성을 유지한 것으로 판단된다.
3-4 데이터 세트에 대한 이미지 품질 평가 결과는 PSNR 21.82, SSIM 0.923, LPIPS 0.126의 평균값을 기록하였다. 이는 앞서 분석한 3-1 세트(PSNR 28.71, SSIM 0.939, LPIPS 0.077) 및 3-3 세트(PSNR 27.48, SSIM 0.893, LPIPS 0.103)에 비해 전반적으로 열악한 품질을 나타낸다. 특히 PSNR 값이 22 이하로 전반적으로 낮아, 원본 영상 대비 왜곡이 크고 신호 손실이 많았음을 시사하며, LPIPS 값이 평균 0.126으로 가장 높게 나타나 시각적으로도 원본과의 유사성이 가장 떨어지는 것으로 평가되었다.
SSIM 역시 3-1 세트보다 0.016p, 3-3 세트보다 0.03p가량 낮게 나타나, 이미지의 구조적 유사성에서도 상대적으로 낮은 품질을 보였다. 특히 3-4 세트의 마지막 프레임(60f)에서는 PSNR 21.47, SSIM 0.902, LPIPS 0.164로 세 지표 모두에서 가장 낮은 품질을 기록하였으며, 이는 렌더링 결과가 원본과 큰 차이를 보였음을 보여준다.
이와 같은 결과는 3-4 세트가 다른 실험군에 비해 렌더링 품질이 전반적으로 낮고, 프레임 간 일관성도 부족함을 나타낸다. 특히 LPIPS 수치가 지속적으로 높은 수준을 유지한 점은 사람의 시각 인지 기준에서도 원본과의 유사성이 떨어진다는 점을 뒷받침한다. 따라서, 정량적 지표 기반의 비교 결과에 따르면 3-4 데이터 세트는 3-1 및 3-3에 비해 화질 재현 성능이 가장 낮은 것으로 판단된다.
이에 대한 결과를 종합적으로 분석한다면 촬영 세팅시 단색 배경보다는 소품이나 마커 배경과 같은 주변 환경 세팅이 추가될 때 좀 더 고품질의 결과를 얻을 수 있으며 마커보다는 디테일과 뎁스가 많은 여러 소품을 배경으로 두었을 때 그 효과가 더욱 클 것으로 보인다.
앞서의 실험 결과를 정리해보면 다음과 같다. 3DGStream 코드 구조를 기반으로 직선형 카메라 리그로 배치하였을 때 프레임별로 스플릿의 움직임을 추적하여 움직이는 다이나믹 씬 결과물이 생성되었으나 전체적으로는 스틸이미지 만으로 생성한 3DGS보다는 품질 퀄리티가 좋지는 않으며, 후반 프레임으로 갈수록 스플릿이 흩어지고 품질이 떨어지는 경우들이 많았다.
카메라의 배치는 직선형으로 카메라 간의 간격이 좁을수록 좋은 결과물을 보였으며, 카메라의 높이 자체는 큰 영향을 끼치지 않았다. 다만 인물의 일부를 완전히 가리는 소품이나 구조물들이 있을 경우 품질 저하에 영향을 미칠 수 있다. 빈 배경보다는 다양한 소품이나 마커와 같은 오브젝트들을 배경에 배치하는 것이 좋은 품질을 보였는데, 소품과 마커를 비교했을 때에는 디테일이 많은 소품들이 좀 더 좋은 효과를 보인다고 볼 수 있다.
4-2 연구 결과의 실제 설치 적용
앞서의 실험 결과를 반영하여 3개의 카메라 2쌍을 40cm 간격으로 직선형으로 배치할 수 있도록 그림4에서처럼 6개의 카메라를 단 리그 한 세트씩 총 4쌍의 세트로 24개의 카메라를 배치할 수 있도록 하되, 촬영할 대상에 따라 간격이나 각도를 조절할 수 있도록 리그에 바퀴를 달아 배치를 조절할 수 있도록 카메라 리그를 세팅하였다.

Conceptual of 4DGS camera rig
이번 실험에서는 직선형의 구조를 사용한 경우에만 프레임 별로 움직임이 생성되었지만 실제 복원 결과물을 확인해보았을 때 카메라가 주로 비추는 전면부 외에 측면과 후면 등 카메라에 담기지 않는 부분의 정확성은 떨어지는 문제점을 볼 수 있었다. 향후 기술적 연구를 통해 측면과 후면, 상단 부분의 복원도 보완할 수 있도록 후면과 측면의 촬영 데이터를 얻기 위해 양 측면에 카메라 리그 2 세트를 추가로 구성하고, 전면부 리그의 상단에 추가로 카메라를 한 대씩 추가하였다. 모든 카메라 거치대에는 볼 헤드를 사용해 피사체에 따라 카메라 각도를 조절할 수 있도록 그림 4와 같이 세팅하였다.
카메라 리그를 그림 5(a)와 같이 제작하여 스튜디오에 설치하고 전면부의 카메라 리그들을 실험의 인조데이터 배치와 동일하게 배치한 뒤 실제 인물 모델과 함께 실제 데이터 세트를 촬영하였다. 촬영한 데이터 세트를 사용하여 4DGS로 복원한 결과 그림 5(b), (c)처럼 인조데이터 셋의 결과물과 마찬가지로 움직이는 다이나믹씬 결과물을 생성할 수 있음을 확인하였다. 생성한 결과물 이미지는 그림 5와 같다.

A photo of the rig actually produced(a), Example of a reconstructed result image using photographed data(b,c)
4-3 연구의 한계 및 후속 연구 제안
본 논문의 실험은 실험 장비를 제작하기 전에 사전적인 환경 요소를 도출하기 위하여 인조데이터를 사용해 여러 조건들을 비교실험한 사전 실험의 성격으로, 정제된 인조데이터 환경에서 하나의 남성 모델로 72프레임 가량의 간단한 동작들을 대상으로 실험하였기에 일반적인 적용에는 한계가 있다. 후속 연구에서는 실제로 촬영 장비를 사용하여 제작한 실제데이터에서 본문으로 도출한 조건들이 똑같이 적용되는지를 확인해야 할 것이다. 또한 여성이나 어린이, 동물 등 다양한 모델의 조건이나, 동작의 종류와 속도, 동선에 따른 결과 비교, 스튜디오가 아닌 야외촬영 등 촬영 환경에 따른 비교 등 다양한 변수 추가 실험을 통해 실제 인물과 환경을 촬영하여 4D-NeRF로 제작하기 위한 최적 조건들을 도출하기 위한 연구 역시 필요할 것이다.
Ⅴ. 결 론
D-NeRF와 4DGS의 연구를 위한 목적으로 다양한 각도에서 동시에 여러 개의 카메라를 통해 영상을 촬영하기 위해서 본 연구에서는 가상의 3D 카메라와 모델을 통해 실제 카메라와 환경을 세팅할 시 고려해야 할 요건들을 실험하고 이를 바탕으로 실제 카메라를 배치하여 리그를 제작하였다.
실험 결과를 정성적 정량적 분석한 결과, 카메라 배치 조건은 유일하게 직선형으로 배치하였 때에만 프레임 별 움직임이 생성되었으며 움직이는 씬의 프레임 별 렌더링 품질은 스틸보다는 낮은 품질로 생성되었다. 카메라 프레임과 소품이 인물의 일부를 완전히 가리지 않는다면 카메라의 높이는 품질에서 큰 차이를 보이지 않았다. 그리고 인물의 배경은 빈 배경보다는 디테일과 뎁스가 많은 소품을 배치할수록 고품질의 결과를 생성하였다.
최근 산업 현장에서 쓰이는 범용 영상 제작 프로그램에서도 3DGS 지원이 차츰 확장되고 있지만, 현재의 D-NeRF와 4DGS에 대한 기술 연구가 이제 막 시작되고 있는 만큼 적용 가능성에 대한 연구도 아직 많지 않다. 실제 제작된 D-NeRF와 4DGS 결과물은 프레임마다 독립된 PLY 파일이 생성되며, 이 프레임 별 PLY 파일을 연속으로 재생하여 영상을 확인할 수 있는 방법은 현재로서는 전용의 프로그램에서만 가능한 상황이다. 하지만 움직이는 D-NeRF와 4DGS 데이터를 활용하고자 하는 요구에 따라 활발히 연구가 되고 있는 분야이므로, D-NeRF와 4DGS의 퀄리티와 속도, 데이터 호환 방법이 지속적으로 연구되고 있으며, 곧 주요 영상 제작 관련 프로그램에서도 D-NeRF와 4DGS에 대한 기술 지원이 곧 이루어질 것으로 예측된다.
또한 인조데이터에서는 모든 카메라가 동일한 프레임 수와 동일한 타이밍에 정확한 초점에 맞춘 또렷한 렌더 결과물을 제작할 수 있었지만 실제 카메라 리그를 제작하고 영상을 촬영하는 과정에서는 카메라의 동기화, 초점 문제와 같은 물리적 세팅에서의 많은 변수가 발생할 수 있으므로 실제 촬영 결과물을 바탕으로 한 카메라 리그 개선은 후속 연구에서 이루어질 수 있을 것이다.
Acknowledgments
본 연구는 문화체육관광부 및 한국콘텐츠진흥원의 2024년 도 문화체육관광 연구개발사업으로 수행되었음(과제명: Near Real 4D Nerf 기반의 VFX시스템 ‘WITH’ 개발 인력 양성, 과제번호: RS-2024-00349479, 기여율: 100%)
References
-
B. Mildenhall, P. P. Srinivasan, M. Tancik, J. T. Barron, R. Ramamoorthi, and R. Ng, “NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis,” in Proceedings of the 16th European Conference on Computer Vision (ECCV 2020), Glasgow: UK, pp. 405-421, August 2020.
[https://doi.org/10.1007/978-3-030-58452-8_24]

-
B. Kerbl, G. Kopanas, T. Leimkuhler, and G. Drettakis, “3D Gaussian Splatting for Real-Time Radiance Field Rendering,” ACM Transactions on Graphics, Vol. 42, No. 4, 139, pp. 1-14, 2023.
[https://doi.org/10.1145/3592433]
- Time Magazine. NVIDIA Instant NeRF: The Best Inventions of 2022 [Internet]. Available: https://time.com/collection/best-inventions-2022/6225489/nvidia-instant-nerf/, .
-
S. J. Cho, D. B. Kim, “Study on Trends in NeRF and 3DGS Technologies and Content Application Cases,” Design Research, Vol. 9, No. 4, pp. 165-180, 2024.
[https://doi.org/10.46248/kidrs.2024.4.165]
-
E. Tretschk, A. Tewari, V. Golyanik, M. Zollhöfer, C. Lassner, and C. Theobalt, “Non-Rigid Neural Radiance Fields: Reconstruction and Novel View Synthesis of a Dynamic Scene From Monocular Video,” in Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal: Canada, pp. 12939-12950, 2021.
[https://doi.org/10.1109/ICCV48922.2021.01272]
-
K. Park, U. Sinha, P. Hedman, J. T. Barron, S. Bouaziz, D. B Goldman, ... and S. M. Seitz, “HyperNeRF: A Higher-Dimensional Representation for Topologically Varying Neural Radiance Fields,” ACM Transactions on Graphics (TOG), Vol. 40, No. 6, pp. 1-12, December 2021.
[https://doi.org/10.1145/3478513.348048]
-
A. Pumarola, E. Corona, G. Pons-Moll, and F. Moreno-Noguer, “D-NeRF: Neural Radiance Fields for Dynamic Scenes,” in Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville: TN, pp. 10318-10327, November 2021.
[https://doi.org/10.1109/CVPR46437.2021.01018]
-
J. Luiten, G. Kopanas, B. Leibe and D. Ramanan, “Dynamic 3D Gaussians: Tracking by Persistent Dynamic View Synthesis,” in Proceedings of the 2024 International Conference on 3D Vision (3DV), Davos: Switzerland, pp. 800-809, March 2024.
[https://doi.org/10.1109/3DV62453.2024.00044]
-
G. Wu, T. Yi, J. Fang, L. Xie, X. Zhang, W. Wei, ... and X. Wang, “4D Gaussian Splatting for Real-Time Dynamic Scene Rendering,” arXiv:2310.08528, , 2024.
[https://doi.org/10.48550/arXiv.2310.08528]
-
T. Xie, Z. Zong, Y. Qiu, X. Li, Y. Feng, Y. Yang, and C. Jiang, “PhysGaussian: Physics-Integrated 3D Gaussians for Generative Dynamics,” in Proceedings of the 2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle: WA, pp. 4389-4398, June 2024.
[https://doi.org/10.1109/CVPR52733.2024.00420]
-
T. Kanade, P. Rander and P. J. Narayanan, “Virtualized Reality: Constructing Virtual Worlds from Real Scenes,” in IEEE MultiMedia, Vol. 4, No. 1, pp. 34-47, March 1997.
[https://doi.org/10.1109/93.580394]
-
J. Carranza, C. Theobalt, M. A. Magnor, and H. P. Seidel, “Free-Viewpoint Video of Human Actors,” ACM Transactions on Graphics (TOG), Vol. 22, No. 3, pp. 569-577, July 2003.
[https://doi.org/10.1145/882262.882309]
- N. Lievendag. CES 2018: Intel Studio’s 10,000 sq. ft. Volumetric Video Capture Area for VR/AR [Internet]. Available: https://www.3dmag.com/news/intel-studio-10000-sq-ft-volumetric-video-capture-area-vrar/, .
- J. Roettgers. 106 Cameras, Holograms and Sticky Tape: Inside Microsoft’s Mixed Reality Capture Studios [Internet]. Available: https://variety.com/2018/digital/features/microsoft-mixed-reality-capture-behind-the-scenes-1202784950/, .
-
M. Işık, M. Rünz, M. Georgopoulos, T. Khakhulin, J. Starck, L. Agapito, and M. Nießner, “HumanRF: High-Fidelity Neural Radiance Fields for Humans in Motion,” ACM Transactions on Graphics (TOG), Vol. 42, No. 4, 160, pp. 1-12, 2023.
[https://doi.org/10.1145/3592415]
-
S. Aljoscha, “3D Video and Free Viewpoint Video—From Capture to Display,” Pattern Recognition, Vol. 44, No. 9, pp. 1958-1968, 2011.
[https://doi.org/10.1016/j.patcog.2010.09.005]
- Y. H. Seo, “Volumetric Live-Action 4D Imaging Technology,” Broadcasting and Media Magazine, Vol. 26, No. 2, pp. 56-66, 2021.
저자소개

2006년:이화여자대학교 조형예술대학 시각정보디자인 전공 학사
2010년:이화여자대학교 대학원 (디자인학석사)
2021년:이화여자대학교 대학원 (디자인학박사-영상디자인)
2024년~현 재: 홍익대학교 영상커뮤니케이션대학원 연구교수
※관심분야:애니메이션, 뉴미디어디자인, XR, NeRF와 3DGS 등

2018년:한국기술교육대학교, 소프트웨어학과 학사
2024년~현 재: ㈜스팩스페이스(연구원)
※관심분야:컴퓨터비전, 컴퓨터 그래픽스, NeRF, Gaussian Splatting

2018년:홍익대학교 공과대학 도시공학전공 학사 (공학학사)
2022년:홍익대학교 영상·커뮤니케이션대학원 영상디자인전공 석사 (미술학석사)
2024년:홍익대학교 일반대학원 영상·인터랙션전공 박사과정생
2022년~현 재: 에이치원스튜디오 대표
2023년~현 재: 명지대학교 스포츠·예술대학 디자인학부 비주얼커뮤니케이션디자인전공 겸임교수
※관심분야:3D Gaussian Splatting & NeRF, 방송 및 영상, 모션그래픽, VFX 등

2022년:조지아공과대학교 컴퓨터공학 인공지능 세부전공 석사
2010년:뉴욕주립대 경제학과 학사
2015년~2017년: SK경영경제연구소
2017년~2018년: 로아컨설팅
2017년~2021년: 열두시반(CEO)
2018년~2020년: 미래에셋금융서비스
2021년~현 재: ㈜스팩스페이스(CEO)
※관심분야:VFX, 컴퓨터비전, NLP, Gaussian Splatting

2001년:이화여자대학교 조형예술대학교, 정보디자인과 시각디자인 전공 학사
2004년:School of Visual Arts, MFA Computer Art 석사
2014년:이화여자대학교 일반대학원, 영상디자인 전공, 디자인학 박사
2004년~2006년: MTV Networks, Nickelodeon, US &Korea
2006년~2011년: CJ ENM, 투니버스
2011년~2013년: Walt Disney Company Korea
2016년~2017년: 동국대학교 교수
2018년~현 재: 홍익대학교 영상·커뮤니케이션학과 교수
※관심분야:방송 및 영상 브랜드 마케팅, 방송영상 및 애니메이션 제작, VFX, 영상 융합 디자인, AI, NeRF